超分FSRCNN的简介
这是一篇译文,原文Review:FSRCNN(Super Resolution)
本文主要用来概述一篇实时超分辨率的实现FSRCNN,全称Fast Super-Resolution Convolutional Neural Network,FSRCNN 发表于2016年的ECCV,目前为止有近300次的引用。 FSRCNN有着一个相对浅的网络结构,浅网络层让我们比较好理解每一个网络层的用途。与SRCNN相比,它重建后的图像质量更高。
对比SRCNN,FSRCNN-s(FSRCNN小模型版本),FSRCNN-s 有着更好的PSNR(图像质量),更快的处理时长。 对比 SRCNN-Ex(SRCNN优质版本)和 FSRCNN,FSRCNN的结果PSNR更好,处理速度更快。 所以,来看下FSRCNN是如何达到质量和速度双优的
下文包含如下内容:
- SRCNN 简述
- FSRCNN 网络架构
- 如何利用 1x1 卷积对网络进行压缩和扩大
- 如何利用多个 3X3 卷积实现非线性映射
- 对比实验
- 结论
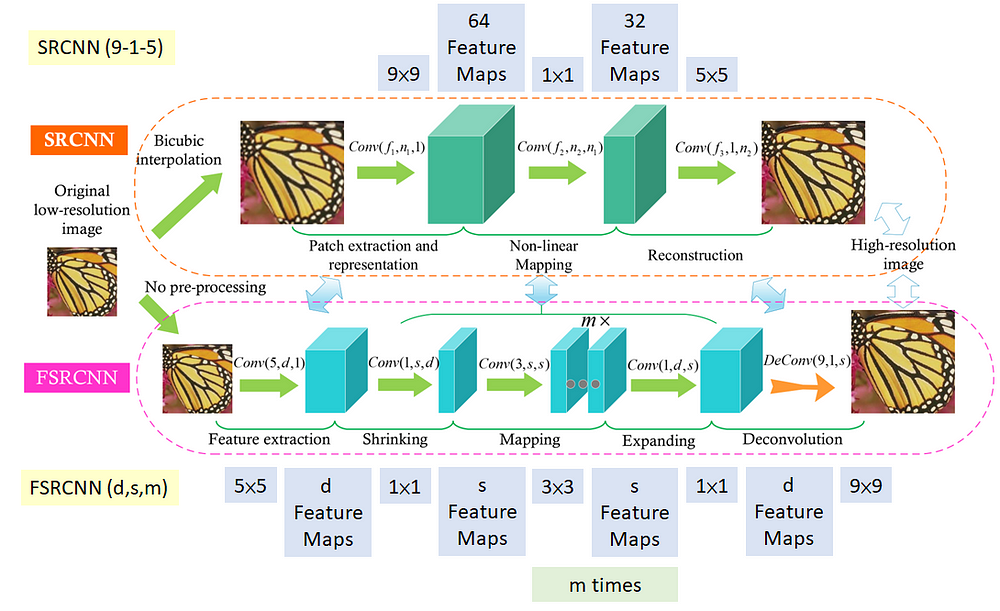
上图是 SRCNN 和 FSRCNN 的网络架构图。其中 Conv(f,n,c)表示该卷积: 卷积大小为fxf, 有n个过滤器以及c个输入通道。
1. SRCNN简述
SRCNN 的处理过程如下:
- 对输入图片利用双立方采样做上采样,使得其分辨率为目标分辨率
- 然后分别利用 9x9, 1x1, 5x5 的卷积来提高图片质量。其中 1x1 卷积是用来把低分辨率(LR)图像向量非线性映射为高分辨率 (HR) 图像向量.
计算复杂度为:
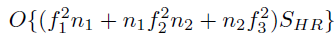
计算复杂度和HR图像大小成线性比例,SHR。HR图像越大,复杂度越高。
2. FSRCNN 网络结构
FSRCNN 包含如下五个主要处理步骤:
- 特征提取:利用一个 5x5 卷积代替 SRCNN 中的双立方差值
- 压缩:利用 1x1 卷积把特征层从 d 压缩为 s,其中 s 小于 d
- 非线性映射:多个 3x3 网络层代替单个的宽网络层
- 扩大: 1x1 卷积把特征层从 s 扩大为 d
- 反卷积: 利用 9x9 过滤器重建 HR 图像
以上结构就是 FSRCNN(d,s,m). 其计算复杂度如下:
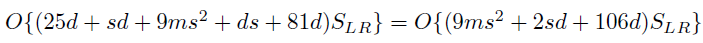
可见复杂度和 LR 图像大小成线性比例,SLR,所以它的复杂度小于 SRCNN
网络中激活函数是 PReLU. PReLU意为带参数的ReLu,目的是比 ReLU 更好。(更多关于 PReLu 的内容, 请参照)
代价函数是均方误差(MSE):
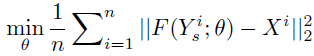
3. 如何利用 1x1 卷积对网络进行压缩和扩大
假设我们在不使用 1x1 卷积的情况下运行 5x5 卷积,如下所示:
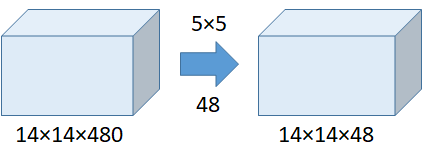
计算次数 = (14x14x48)x(5x5x480) = 112.9M
如果使用 1x1 卷积:
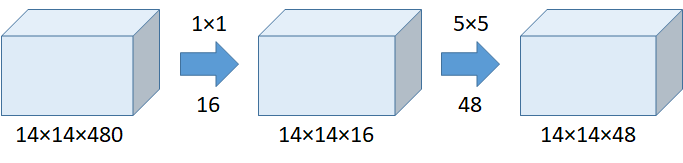
1x1 卷积计算次数 = (14x14x16)x(1x1x480) = 1.5M 5x5 卷积计算此时 = (14x14x48)x(5x5x16) = 3.8M 两者总共计算次数 = 1.5M + 3.8M = 5.3M,比只使用 5x5 足足少了 112.9M 次计算。
论文Network-In-Netwrok建议使用 1x1 卷积引入更多的非线性并改善性能,而GoogleNet建议 1x1 卷积有助于在保证效果的同时减小模型大小。(GoogleNet简述)。
因此在两个卷积层之前使用 1x1 卷积来减少连接(参数)。通过减少参数,我们只需要更少的乘法和加法运算,最终加速网络。这就是 FSRCNN 比 SRCNN 快的原因。
4. 如何利用多个 3x3 卷积实现非线性映射
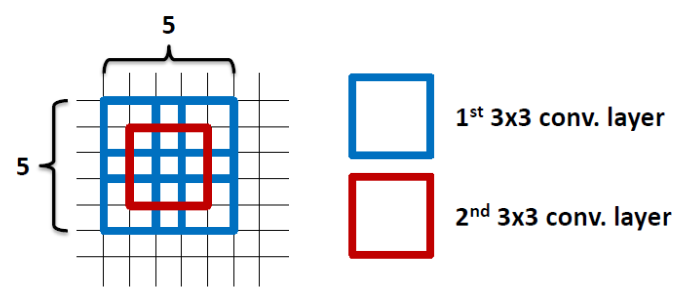
如上图所示通过使用2层 3x3 滤波器来覆盖 5x5 滤波器的区域,让参数数量变少。
1层 5x5 滤波器的参数数量 = 5x5 = 25 2层 3x3 滤波器的参数数量 = 3x3+3x3 = 18 参数量减少了28%。而更少的参数意味着网络在训练的时候可以更快的收敛,并减少过拟合问题。
5. 对比实验
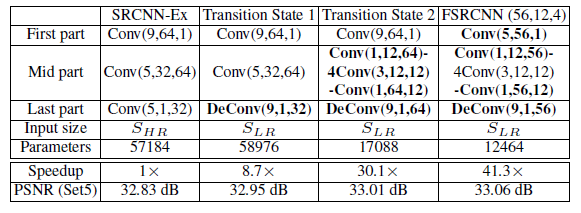
- SCRCNN-Ex: SRCNN 的优质版本,拥有 57184 个参数
- Transition State 1: 使用反卷机,有 58976 个参数,获得更高的PSNR
- FSRCNN (56,12,4): 更小的滤波器,更少的滤波器,有 12464 个参数,更高的PSNR。更重要的参数更少,相对容易收敛。
下表为每个组件的贡献值:
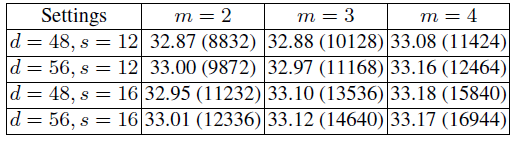
对比各种参数的结果,选取 m=4, d=56, s=12时,可以兼顾HR图像质量(33.16dB)和模型复杂度(12464参数)。
最终我们选用 FSRCNN:FSRCNN (56,12,4),FSRCNN-s:FSRCNN (32,5,1)
结论
- 利用91张放大3倍的图片从头开始训练网络,然后利用利用放大2倍和4倍的100张图反卷积微调网络。
- 数据增强部分,缩放:0.9,0.8,0.7,旋转::90,180,270
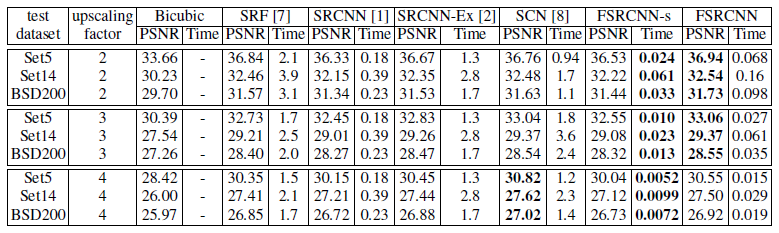
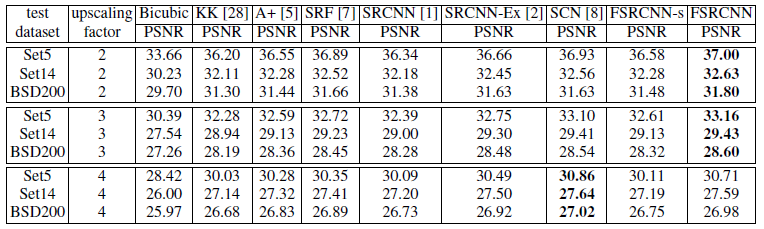
从上述结果可以得出:FSRCNN和FSRCNN-s在放大2倍,3倍效果好。当放大4倍的效果比SCN差一点点。

通过论文中的浅层网络,我们可以了解每种组件的效果,例如1×1卷积和多个3×3卷积。