生成对抗网络
生成对抗网络
Overview
简介
Generative adversarial networks (GANs) 生成对抗网络是机器学习领域最近非常让人兴奋地一项发明。GAN是生成模型:他根据训练数据生成相似的数据。举例来讲,GAN可以生成非常像人脸的照片,尽管生成的人脸不属于世界上任何一个真人,但是人眼真假难分。
下面这些图是GAN生成的。

GAN分成两个部分生成器,判别器,通过生成器来生成数据,通过判别器来判别生成器生成的数据。生成器试图去骗过判别器,而判别器试图保持不被骗。
生成模型
Background: What is Generative Model?
”生成对抗网络”中的“生成”是什么意思?“生成”描述的是一类统计模型,与判别器模型形成对比。
非正式的定义:
- Generative 生成模型用来生成新的数据实例
- Disciminative 判别模型用来判别不同类型数据的真实性
生成模型可以生成新的动物照片,这些照片看起来像真实的动物,而辨别模型可以分辨出一只狗和一只猫。GAN只是生成模型中的一种。
正式一点的定义:给定一组数据实例 X 和一组标签 Y:
- Generative 生成模型得到联合概率 p(X,Y), 如果没有标签,则获得 p(X).
- Discriminative 对抗模型得到条件概率 p(Y|X)
生成模型包括数据自身的分布,并可以返回一个给定的样本属于这个数据分布的可能性有多大。比如,一个典型的生成模型是预测一个序列中下一个单词(通常比GAN要简单一些),它们给单词序列分配一个概率。
判别模型忽略给定实例是否可能出现的问题,仅返回该标签应用于该实例的可能性。
A discriminative model ignores the question of whether a given instance is likely, and just tells you how likely a label is to apply to the instance.
请注意,这是一个非常笼统的定义。有许多生成模型,GAN只是生成模型的一种。
Modeling Probabilites
这两种模型都不需要返回代表概率的数字。你可以通过模仿数据的分布来建立模型。
例如,像决策树这样的判别性分类器可以给一个实例打上标签,而不给这个标签分配一个概率。这种分类器仍然是一个模型,因为它预测的标签分布和真实数据的标签分布接近。
同样,生成式模型可以通过产生令人信服的 “假 “数据来对分布进行建模,这些数据看起来像是从该分布中提取的。
Generative Models Are Hard
与同类别的判别模型相比,生成模型处理的任务更加困难。生成模型需要能够模拟更多信息。 图像生成模型可能会捕获到"看起来像船的东西可能会出现在看起来像谁的东西附近"和“眼睛不太可能出现在额头上”这样的相关性。这些都是非常复杂的分布。而相比之下,判别器可能只需要寻找一些明显的模式,就能学会“帆船”或“非帆船”之间的区别。它可能会忽略生成模型在意的许多关联性。
判别模型试图在数据空间中划定边界,生成模型则试图模拟数据在整个空间中的位置。例如,下图显示了手写数字的判别模型和生成模型。
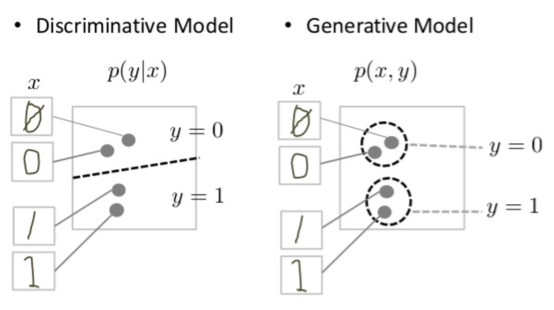
判别器试图在数据空间中画一条先来分别手写0和1.如果它画的线正确,在不需要准确的模拟出实例在数据空间中两边的位置,就可以区分0和1.相比之下,生成模型试图生成接近数据空间中真实对应的数字来产生令人信服的1和0。它必须对整个数据空间的分布进行建模。
GAN提供了一个有效的方法去训练模拟真实数据分布的模型。要弄明白他是怎么工作的我们需要弄清楚GAN的基础架构。
GAN Anatomy
Overview of GAN Structure
GAN 分成两个部分:
- 生成器负责生成数据。生成的数据会当做负样本给判别器
- 判别器学习区分生成器的假数据和真实数据。判别器对生成器生成的不可信的结果进行惩罚。
当开始训练时,生成器生成出看起来明显是假的数据,判别器迅速学习到如何判断生成器的生成数据是假的

当训练继续进行,生成器会生成出可以骗过判别器的数据:

最终,如果生成器训练的很好,判别器会判别不出数据的真假。判别器会开始把假数据判为真,他的精度开始下降。

下图是GAN的完整结构图:

生成器和判别器都是神经网络。生成器的输出直接当做判别器的输入。通过反向传播,判别器的分类提供一个信号去让生成器更新它的权重。
Discirminator
The Discriminator
GAN中的判别器一般是一个简单的分类器。它试图区分真实数据和生成器生成的数据。它可以使用任何适合的分类网络。

Discriminator Training Data
判别器的训练数据有两个来源:
- 真数据 比如人的真实照片。判别器使用这些数据当做训练时的正样本
- 假数据 由生成器生成的数据。判别器使用这些数据当做训练时的负样本
在图三种,两个“样本”框代表这两个输入到判别器的数据源。在判别器训练期间,生成器不进行训练.生成器保持它的weights,生成数据样本给判别器训练。
Traing the Discriminator
判别器连接了两个损失函数。在判别器训练期间,判别忽略生成器loss,只使用判别器loss。生成器loss在训练生成器的时候使用。
在判别训练期间:
- 判别器用来判别真实数据和生成器的生成数据
- 当判别器把真判断为假,或者是把假数据判断为真,判别器 loss 会惩罚判别器
- 判别器通过判别器loss,反向传播判别网络,更新网络权重
Generator
The Generator
GAN的生成器通过判别器的反馈来学习模型,使得判别器判断生成数据为真。 与判别器训练相比,生成器训练过程中需要联合判别器和生成器。GAN的训练包括以下几个部分:
- 随机输入
- 生成网络将随机输入转化为数据
- 判别网络,用来分类生成数据
- 判别器输出
- 生成loss,用来惩罚未能骗过判别器的生成器

Random Input
神经网络需要某种形式的输入.通常我们输入的数据是我们想做的事情,比如我们相对一个样本进行分类或者做一个预测。但是对于一个输出全新数据样本的网络,我们用什么作为输入呢?
一个最基本的GAN的输入是随机噪声。生成器把噪声转换为有意义的输出。通过引入噪声,我们可以从目标样本中的不同地方采样从而让GAN产生各种各样的数据。
实验表明,噪声的分布并不重要,所以我们可以选择一些容易采样的东西,比如均匀分布。为方便起见,对噪声进行采样的空间通常比输出空间的维度小。
Using the Discriminator to Train the Generator
在训练一个神经网络的过程中,我们改变网络的权重以此来降低目标loss。在GAN的训练里面,生成器并不直接连接到我们的目标loss。生成器的结果输入给判别器,判别器最终产生我们想要的结果。生成器loss对那些被判别判断为假的数据进行惩罚。
这个额外的网络必须包含在反向传播中。反向传播过程中通过计算权重对输出的影响来调整权重往正确的方向更新 - 你改变权重,输出会发生怎样的变化。但是一个生成器权重的影响取决于它所送入的判别器权重的影响。所以,反向传播从输出开始,通过判别器回流到生成器。
与此同时,在训练生成器的时候我们不希望改变判别器。对于本来就比较难训练的生成器,再加一个移动的目标,无疑让问题更加的困难。 总结下来我们按照以下步骤训练生成器:
- 采样随机噪声
- 生成器根据随机噪声生成数据
- 生成数据给判别器,判别器对数据进行分类
- 计算判别器分类loss
- 通过判别器,和生成器进行反推,得到梯度。
- 使用梯度来改变生成器的weights 这里描述是一次典型的生成器迭代,在下一节中,我们将看到如何平衡生成器和判别器的训练。
GAN Training
因为GAN包括了两个独立分开的网络,他训练算法需要解决两个复杂的问题:
- GAN 需要同时平衡生成器和判别器的训练
- GAN是否收敛不好定义
GAN的训练是交替进行的:
- 判别器训练1或多个epochs
- 生成器训练1或多个epochs
- 重复步骤1和2,交替训练生成器和判别器
在训练判别器的时候,我们保持生成器固定。此时,判别器训练过程中试图去分辨出数据的真假,他需要知道如何识别出生成器的缺点。对于判别器来说,识别出一个经过彻底训练的生成器的缺点,和识别出一个未经训练的,输出是随机产生的生成器缺点,两者不是同一个问题。
同样的,我们在训练生成器的时候保持判别器固定。否则,生成器将试图优化一个移动的目标,这有可能导致问题永远不会收敛。
正是这种来来回回,使得GAN能够解决原本难以解决的生成问题。我们解决一个简单的分类问题之后,然后去解决更加困难的生成问题。相反,如果你不能训练一个分类器来分辨真实数据和一个初始生成器随机生成数据之间的真假,那么你是没有办法开始训练GAN网络的。
Convergence
随着生成器能力的不断提高,判别器的能力会越来越差,因为判别器不再能分辨出真假。如果生成器完全收敛,那么判别器最终的准确率应该为50%,这个时候,判别器就像是扔一枚硬币来做真假预测。
这种进展给整个GAN的收敛带来了一个问题:随着时间的推移,判别器反馈的意义越来越小。如果GAN继续训练,过了判别器给出完全随机反馈的时间点,那么生成器就会开始在垃圾反馈上进行训练,其自身质量可能会崩溃。
对于一个GAN来说,收敛往往是一种短暂的状态,而不是稳定的状态。
Loss Functions
GAN试图重现一个概率分布。他需要使用损失函数来减小GAN生成的数据分布和真实数据分布之间的距离。 那如何通过损失函数来获得真实分布和GAN生成数据分部之间的差别呢?很多人在研究这个领域,并提出了很多方法。我们这里要讲两个常见的GAN损失函数,这两个损失函数都是在TF-GAN里面实现的。
- minimax loss: 这个损失函数在解释GAN的paper中被使用
- Wasserstein loss: TF-GAN Estimators的默认损失函数。在论文Wasserstein GAN中首次被提出来。
TF-GAN 还实现了很多其他的损失函数。
One Loss Function or Two?
一个GAN有两个损失函数:一个是为了训练生成器,一个是为了训练判别器。那两个损失函数是如何在一起工作,进而最终去影响两个概率分布之间的距离的呢?
我们这里看下损失函数的方案,生成器和判别器的损失来自于测量出两个概率分布之间距离。在这个结构中,生成器只能影响测量距离中的一项内容:反映假数据的分布情况。所在生成器训练的过程中,我们放弃了另外一项:真实数据分布。 生成器和判别器的损失最终看起来是不同的,尽管他们是由同一个单一的公式得出的。
Minimax Loss
在介绍GAN的论文,生成器试图最小化下面的函数,而判别器试图最大化它。
Ex[log(D(x))] + Ez[log(1 - D(G(z)))]
在这个公式中:
- D(x): 判别器对真实数据样本x的概率估计
- Ex: 所有真实数据的期望值
- G(z) 生成器生成的数据
- D(G(z)): 判别器对生成数据的的概率估计
- Ez: 生成器所有随机输入的期望值(实际上,是对所有生成的假数据G(z)的期望值)
- 这个公式是真实数据分布和生成数据分布的交叉熵损失
生成器不能直接影像函数中的 log(D(x)) 项,所以,对生成器来说,最小化上述损失函数相当于最小化 log(1 - D(G(z)))。
在TF-GAN中,请参加 minimax_discriminator_loss 和 minimax_generator_loos 来了解这个损失函数的实现。
Modified Minimax Loss
最初的GAN论文中指出,在GAN训练的早期阶段,当判别器的工作很容易的时候,上述的最小最大化损失函数会导致GAN卡住。因此,该论文建议修改生成器的损失,是生成器尝试最大化 logD(G(z))。
Wasserstein Loss
TF-GAN 默认使用 wasserstein loss
该损失函数是基于GAN(称为"Wasserstein GAN"或“WGAN”)的一个修改,在这个方案中,判别器实际上并不对数据实例进行分类。判别器对每一个数据实例输出一个数字。这个数字不必小于1,也不必大于0,所以我们不能用0.5作为门槛来决定一个实例的真假。判别器训练过程中试图让真实数据的输出比假数据的输出值更大。
因为他不能真正判别出真假,WGAN的判别器应该被称为“评论者”,而不是“判别者”。这种区别在理论上具有很重要的意义,实际上,我们可以将其视为承认损失函数的输入不一定得是概率。
损失函数本身是很简单的:
Critic Loss: D(x) - D(G(z))
判别器试图最大化这个函数。也就是说,他试图最大化判别器对生成器生成数据的输出和判别器对真实数据的输出之间的差别。
Generator Loss: D(G(z))
生成器试图最大化这个函数。也就说,他试图最大化判别器对假数据的输出
在上述函数中:
- D(x) 对真实数据的评价
- G(z) 生成器生成数据
- D(G(z)) 对生成数据的评价
- D输出不需要在0到1之间
- 公式来源于真实分布和生成分布之间的地动距离.
Requirements
Wasserstein GAN(或WGAN)的理论依据要求对整个GAN的权重进行剪裁,使其保持在一个约束的范围内。
Benefits
Wasserstein GANs比基于minimax的GANs更不容易被卡住,并且避免了消失梯度的问题。地动仪距离还有一个优点,那就是它是一个真正的度量:在概率分布空间中对距离的度量。交叉熵不是这个意义上的度量。
Real World GANs
Common Problems
GAN 有一些常见的问题,目前这些常见的问题都在被不同的研究者在积极的研究中。虽然这些问题都没有得到彻底解决,我们提到一些人们已经尝试过的事情。
Vanishing Gradients
研究表明,如果你的判别器太好,那么生成器训练就会因为梯度消失而失败。实际上,一个最佳的判别器并不能为生成器提供足够的信息来取得进步。
Attempts to Remedy
- Wasserstein loss: 设计 Wasserstein loss 的目的是为了在你把判别器训练最佳状态的情况下,防止梯度消失。
- Modified minimax loss: 原GAN论文中提出了对最小损失的修改,以处理梯度消失的问题。
Mode Collapse
通常情况下,我们希望GAN网络产生各种各样的输出。例如,当每次给不同的随机输入给人脸生成器,生成器可以生成不同的人脸。
然而,如果一个生成器产生了一个特别可信的输出,生成器可能会学习只产生这种输出。事实上,生成器总是试图找到一个在判别器看来最可信的输出。
如果生成器开始一次又一次的产生相同的额输出(或一小组输出),那么判别器的最佳策略就是学会始终拒绝该输出。但如果下一代判别器卡在局部最小值,没有找到最佳策略,那么下一代生成器在迭代过程中会很容易生成输出让当前判别器判别出看似合理的结果。
生成器的每一次迭代都会对特定的判别器进行过度优化,而判别器永远无法学会如何摆脱陷阱。结果就是生成器轮流输出一组小的输出类型。这种形式的GAN失败称为模式崩溃。
Attempts to Remedy
以下方法试图迫使生成器扩大其范围,防止其针对单一固定的判别器进行优化。
-
Wasserstein loss: Wasserstein loss 可以缓解模式崩溃的问题,让你把判别器训练到最佳状态而不用担心梯度消失。如果判别器没有卡在局部最小值,它就会学会拒绝生成器稳定的输出。所以生成器必须尝试新的东西。
-
Unrolled GANs: Unrolled GAN 使用的生成器损失函数不仅包含了当前判别器的分类,还包含了未来判别器的输出。因此,生成器不能对单个判别器进行过度优化。
Failure to Converge
如前面GAN训练章节中中所述。GAN经常无法收敛。
Attempts to Remedy
研究者试图使用各种形式的正则化来提高GAN收敛性,包括:
- Adding noise to discriminator inputs: 如 Toward Principled Methods for Training Generative Adversarial Networks.
- Penalizing discriminator weights 如 https://arxiv.org/pdf/1705.09367.pdf
GAN Variations
研究人员不断改进GAN技术以及GAN的用途。以下是GAN的一些变体,让你了解GAN的各种可能性。
Progressive GANs
在渐进式GAN中,生成器的第一层产生分辨率很低的图像,随后各层增加细节。这种技术使GAN的训练速度比类似的非渐进式GAN更快,并产生更高分辨率的图像。
Conditional GANs
条件 GAN 在有标签的数据集上进行训练,需要为每个生成的实例指定标签。例如,一个无条件的MNIST GAN将产生随机的数字,而一个有条件的MNIST GAN可以指定GAN应该产生哪个数字。