音频编解码以及音乐GPU实时可视化效果实现
前言
在一些音乐播放器上(如上学时候用的播放器千千静听)会有一排 直方图 随着音乐节奏忽高忽低的跳动。你会好奇这个直方图的跳动是随着音乐的什么属性来做变换的,貌似有时候和音乐的节奏还挺搭的。要解释清楚这个问题,首先得了解什么声音,以及声音的原理。
声音
声音的原理
根据维基百科上所述:声音是一种波动;当演奏乐器、人说话或者敲击桌面时,声音的振动会引起介质——空气分子有节奏的振动,使周围的空气产生疏密变化,形成疏密相间的纵波,这就产生了声波,这种现象会一直延续到振动消失为止。
声音作为波的一种,频率和振幅就成了描述波的重要属性,频率的大小与我们通常所说的音高对应,而振幅影响声音的大小。声音可以被分解为不同频率不同强度的正弦波的叠加。这种变换(或分解)的过程,称为傅立叶变换(Fourier Transform)。
所以到这里,我们大致明白了音乐播放器上面的直方图其实是声音的频率和振幅的统计图。
声音的特性
- 响度(loudness):人主观上感觉声音的大小(俗称音量),由“振幅”(amplitude)和人离声源的距离决定,振幅越大响度越大,人和声源的距离越小,响度越大。(单位:分贝dB)
- 音调(pitch):声音的高低(高音、低音),由“频率”(frequency)决定,频率越高音调越高(频率单位Hz(hertz),赫兹),人耳听觉范围 20~20k Hz。20Hz以下称为次声波,20k Hz以上称为超声波)例如,低音端的声音或更高的声音,如细弦声。频率是每秒经过给定点的声波数量,它的测量单位为赫兹。1000Hz表示每秒经过给定点的声波有1000个周期
- 音色(Timbre):又称音品,波形决定了声音的音色。声音因不同物体材料的特性而具有不同特性,音色本身是一种抽象的东西,但波形是把这个抽象直观的表现。音色不同,波形则不同。典型的音色波形有方波,锯齿波,正弦波,脉冲波等。不同的音色,通过波形,完全可以分辨的。
- 乐音:有规则的让人愉悦的声音。噪音:从物理学的角度看,由发声体作无规则振动时发出的声音;
音频编解码
音频的编解码器需要分成硬件,软件两个部分讨论。硬件部分,音频编码器芯片(ADC)会把接收到的声波转换成PCM数据, 由于PCM占用存储资源太大,不利于传输和存储,所以需要利用音频编解码器软件对PCM数据进行压缩,得到如 FLAC/MP3/OGG 的音频文件。当我们播放一段数字音频文件的时候,则需要先进行软解码,也就是对压缩过的音频文件(FLAC/MP3/OGG)先解码成PCM,然后传送解码后的PCM给音频解码器(DAC),解码器将数字信号转换为模拟信号。
音频硬编码过程
信号的数字化就是将连续的模拟信号转换成离散的数字信号, 一般需要完成采样、量化和编码三个步骤,如下图所示。
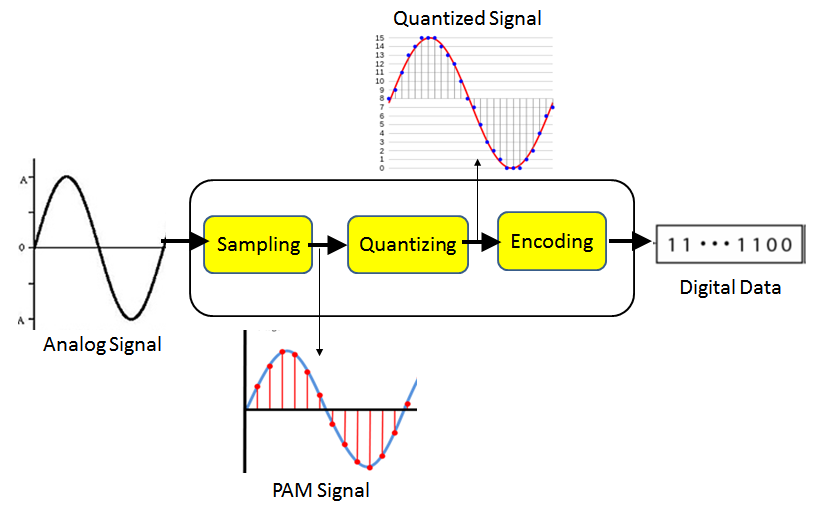
- 采样是指用每隔一定时间间隔的信号样本值序列来代替原来在时间上连续的信号。
- 量化是用有限个幅度近似表示原来在时间上连续变化的幅度值,把模拟信号的连续幅度变为有限数量,有一定时间间隔的离散值。
- 编码则是按照一定的规律,把量化后的离散值用二进制数码表示。
上诉数字化过程称为脉冲编码调制(Pulse Code Modulation,缩写PCM)
PCM 的码率
- 采样率值 × 采样大小值 × 声道数 bps = 码率
- 例如: 一个采样率为44.1KHz,采样大小为16bit,双声道的PCM编码的WAV文件,它的数据速率则为 44.1K×16×2 =1411.2 Kbps。这表示存储一秒钟采样率为44.1KHz,采样大小为16bit,双声道的PCM编码的音频信号,需要176.4KB的空间,1分钟则约为10.34M
MP3
MP3全称是MPEG-1orMPEG-2 Audio Layer III,它被设计来大幅降低音频数据量,它舍弃PCM音讯资料中,对人类听觉不重要的资料,从而达到了压缩成较小的档案。而对于大多数用户的听觉感受来说,MP3的音质与最初的不压缩音频相比没有明显的下降。
音频处理
音频傅立叶变换
了解了声音和音频编解码的基础知识之后,我们可以开始对音频进行相关应用处理了。那如何处理音频呢?首先用Audacity软件打开一段音频,会看到如下图所示的波形图。你会想,这乱糟糟,看起来没啥规律可循的波形的该如何处理。

就像我们处理图片的时候,会把像素点颜色分解成RGB三个通道(或者YCbCr,Lab 等其他颜色空间)进行处理一样,在处理音频的时候,我们需要对音频的波形进行分解。根据声音的特性,不同物体发出的声音频率范围是不一样的,如下图是不同乐器的频率范围:
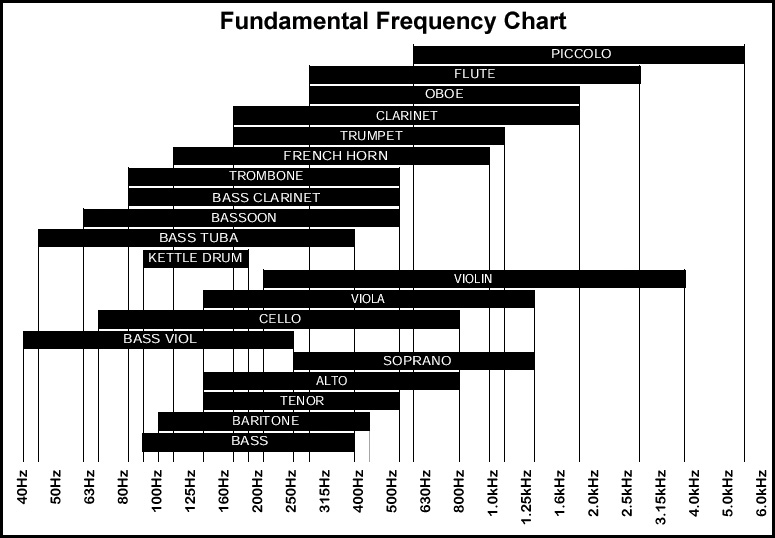
所以我们可以把音频从时域转换到频域,然后对分解出来的各个频率进行操作。这里需要借助傅立叶变换完成音频从时域到频域的转换。
看不懂傅立叶变换的数学公式也没有关系,只要记住下面这张图就好。
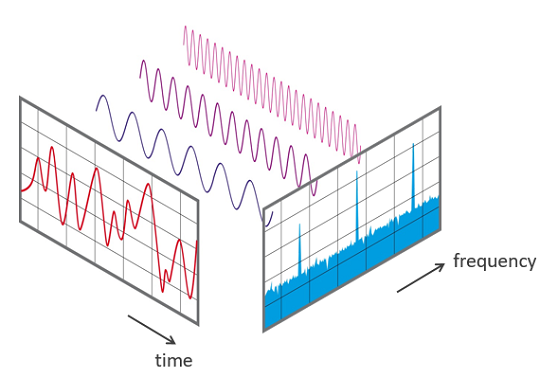
如上图,对左边红色的音频时域声波进行傅立叶变换之后,分解成了一系列正弦波。而右边蓝色部分是针对分解的一系列正弦波的统计图,其中横轴是频率,纵轴是振幅。有了这张频谱图,我们可以很方便的处理音频了(如消除某一段频率等等)。
Demo
有了上面对音频做傅立叶变换后的频率数组,我们可以开始去实现一个音乐实时可视化Demo了。考虑到性能,以及跨平台,我们利用GPU搭配OpenGL编程去实现Demo。实现步骤如下图所示:

获取PCM数据
在iOS上,利用AVFoundation中的AVAudioEngine获取音乐的pcmbuffer,然后利用Accelerate framework中提供的DSP信号处理api,对pcmbuffer进行傅立叶变换。
加载音乐
NSString * audioPath = [[NSBundle mainBundle] pathForResource: @"bgm" ofType: @".mp3"];
AVAudioEngine * engine = [AVAudioEngine new];
AVAudioFile * audioFile = [[AVAudioFile alloc] initForReading: [NSURL fileURLWithPath: audioPath] error: nil];
AVAudioPCMBuffer * audioPCMBuffer = [[AVAudioPCMBuffer alloc] initWithPCMFormat: audioFile.processingFormat
frameCapacity: (AVAudioFrameCount)audioFile.length];
[audioFile readIntoBuffer: audioPCMBuffer error: nil];
AVAudioPlayerNode * audioPlayerNode = [AVAudioPlayerNode new];
[engine attachNode: audioPlayerNode];
// Connect Nodes
AVAudioMixerNode *mixerNode = [engine mainMixerNode];
[engine connect: audioPlayerNode to: mixerNode format: audioFile.processingFormat];
[audioPlayerNode scheduleBuffer: audioPCMBuffer completionHandler:^{
NSLog(@"scheduleBuffer");
}];
// Start engine
NSError *error;
[self.engine prepare];
[self.engine startAndReturnError: &error];
if (error) {
NSLog(@"error:%@", error);
}
获取 PCMBuffer
int bufferSize = 1024;
[mixerNode installTapOnBus: 0
bufferSize: bufferSize
format: [mixerNode outputFormatForBus: 0]
block: ^(AVAudioPCMBuffer * _Nonnull buffer, AVAudioTime * _Nonnull when) {
float * magnitudes = [FFTHelper performFFT: buffer];
}];
执行 FFT
+ (float *) performFFT: (AVAudioPCMBuffer *) buffer {
if (buffer == NULL) {
return NULL;
}
int frameLength = buffer.frameLength;
long nOver2 = frameLength / 2;
vDSP_Length fftLength = nOver2;
float * imag = (float *) calloc(frameLength, sizeof(float));
DSPSplitComplex splitComplex;
splitComplex.realp = buffer.floatChannelData[0];
splitComplex.imagp = imag;
int log2n = (vDSP_Length)(floor(log2((float)frameLength)));
int radix = (FFTRadix)kFFTRadix2;
FFTSetup weights = vDSP_create_fftsetup(log2n, radix);
vDSP_fft_zip(weights, &splitComplex, 1, log2n, (FFTDirection)FFT_FORWARD);
float fftNormFactor = 1.0 / (2 * fftLength);
vDSP_vsmul(splitComplex.realp, 1, &fftNormFactor, splitComplex.realp, 1, fftLength);
vDSP_vsmul(splitComplex.imagp, 1, &fftNormFactor, splitComplex.imagp, 1, fftLength);
float * magnitudes = (float *) calloc(fftLength, sizeof(float));
//Convert the fft data to dB
vDSP_zvmags(&splitComplex, 1, magnitudes, 1, fftLength);
float kAdjust0DB = 1.5849e-13;
//In order to avoid taking log10 of zero, an adjusting factor is added in to make the minimum value equal -128dB
vDSP_vsadd(magnitudes, 1, &kAdjust0DB, magnitudes, 1, fftLength);
float one = 1;
// vDSP_vdbcon: Vector convert to decibels, power, or amplitude.
vDSP_vdbcon(magnitudes, 1, &one, magnitudes, 1, fftLength, 0);
free(imag);
vDSP_destroy_fftsetup(weights);
return magnitudes;
}
上传FFT数据到GPU
拿到频谱数据之后,需要利用shader来实现音乐可视化的效果。当中如何把频谱数据上传到GPU是一个问题,因为频谱数据一个长达1k的数组,直接用uniform float[]来上传,性能很差。这里有一个比较tricky的做法是把频谱数据存储到一张空白图片上,然后把图片转换成texture,再上传texture到GPU,这样就可以优化上传频谱数组性能差的问题。
// Passing the data to the GPU
-(void)load: (float *) data length: (int) length width: (int) width height: (int) height slot: (GLenum) slot {
GLuint texture = 0;
GLubyte * raw = (GLubyte *) malloc (sizeof (GLubyte) * length * 4);
for (int i = 0; i < length; i++) {
GLubyte color = GLubyte(data[i] * 255.0);
raw[4*i+0] = color; // R
raw[4*i+1] = color; // G
raw[4*i+2] = color; // B
raw[4*i+3] = color; // A
}
glActiveTexture (slot)
glGenTextures (1, &texture)
glBindTexture (GLenum (GL_TEXTURE_2D), texture);
glTexParameteri (GLenum (GL_TEXTURE_2D), GLenum (GL_TEXTURE_WRAP_S), GL_REPEAT);
glTexParameteri (GLenum (GL_TEXTURE_2D), GLenum (GL_TEXTURE_WRAP_T), GL_REPEAT);
glTexParameteri (GLenum (GL_TEXTURE_2D), GLenum (GL_TEXTURE_MAG_FILTER), GL_LINEAR);
glTexParameteri (GLenum (GL_TEXTURE_2D), GLenum (GL_TEXTURE_MIN_FILTER), GL_LINEAR);
glTexImage2D (GLenum (GL_TEXTURE_2D), 0, GL_RGBA, GLsizei (width), GLsizei (height), 0, GLenum (GL_RGBA), GLenum (GL_UNSIGNED_BYTE), raw);
free (raw); raw = NULL;
}
可视化效果
最后在shader中解析texture,得到频谱数据,并绘制直方图,就可以做出音乐播放器上的直方图效果啦,如下图:
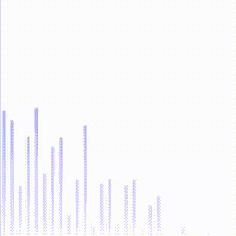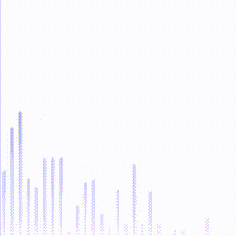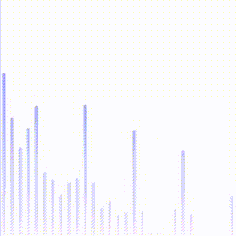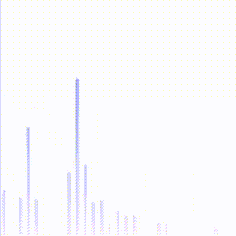
效果比较素,更加华丽的一些关于音乐可视化的效果可以翻翻shadertoy.com,上面有很多绚丽的效果。如下图:
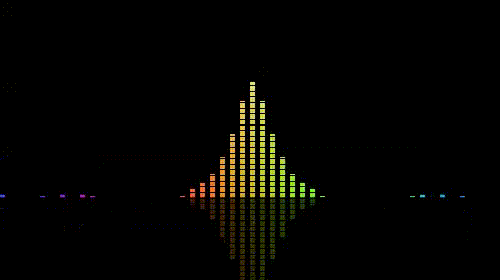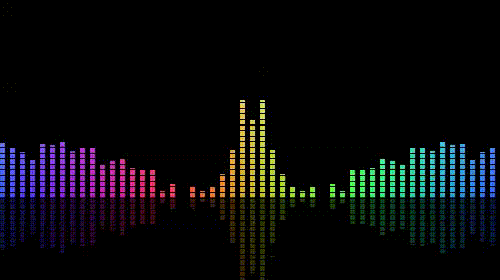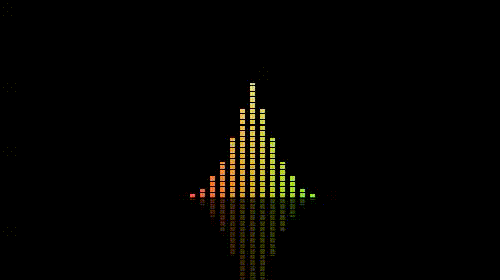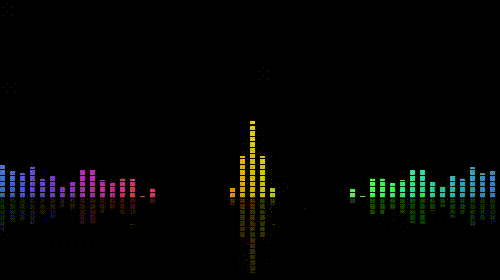
以上。