理解 Disco Diffusion
Disco Diffusion
Disco Diffusion是 github 上面一个开源项目,用户通过该项目输入一段文字便可以生成一张和文字有一定相关性的图片,且图片有一定的艺术性。Disco Diffusion 是基于OpenAI Guided Diffusion 项目基础上做的研发。其中 disco 是该项目jupter notebook的名称。
Disco Diffusion项目中的diffusion模型使用的是Katherine Crowson提供的,他利用获得的artstation网站上的数据集,在OpenAI 512x512模型上进行fine-tuned,得到disco diffusion中的diffusion模型。Disco Diffusion项目中还利用OpenAI的另外一篇工作CLIP,通过CLIP来关联Image和Text,使得生成的图片具有prompt text的语义信息。
Disco Diffusion演进过程中的主要优化点:
- 优化了augmentation,以及把 timestep 从1000压缩到15-100个 timestep
- 使用较短的运行时间,并且提升了diffusion的生成质量
- 一次性加载多个CLIP模型,多个CLIP模型可以提高生成图accuracy
要理解Disco Diffusion的工作原理,需要先了解DDPM,Guided Diffusion,以及CLIP几个模型的工作原理。
Diffusion模型与DDPM
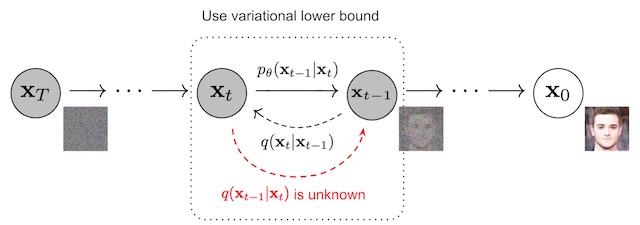
扩散模型包括两个过程,从信号逐步到噪声的扩散(正向)过程/(diffusion/forward process) 和从噪声逐步到信号的 逆向过程(reverse process)。这两年的扩散模型基本都是基于Google的DDPM (Denoising Diffusion Probabilistic Model)框架所设计。
逆向过程
逆向过程从一张随机高斯噪声图片 xT 开始,通过逐步去噪生成最终的结果 x0。这个过程是一个Markov Chain,可以被定义为:
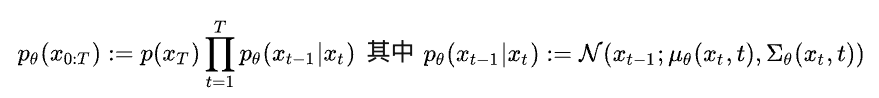
这个过程可以理解为,我们根据 xt 作为输入,预测高斯分布的均值和方差,再基于预测的分布进行随机采样得到 xt-1 。通过不断的预测和采样过程,最终生成一张真实的图片。
正向/扩散过程
扩散过程采用的是一个固定的 Markov chain 形式,过程中逐步向图片添加高斯噪声:
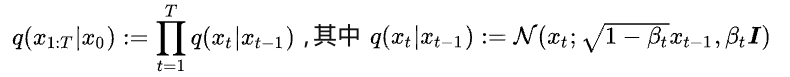
在DDPM中,βt 是预先设置的定值参数。扩散过程的一个重要特性是可以直接采样任意时刻t下的加噪结果 xt 。将

可以得到
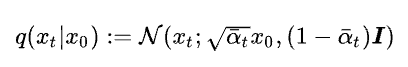
这个封闭式的公式使得我们可以直接获得任意程度的加噪图片,方便后续的训练。
模型训练
为了实现基于扩散模型的生成,DDPM采用了一个U-Net结构的Autoencoder来对t时刻的噪声进行预测。网络训练时采用的训练目标非常简单:
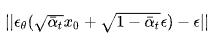
此处ε是高斯噪声。噪声预测网络输入是加噪图片,目标是预测所添加的噪声。训练目标是希望预测的噪声和真实的噪声一致。最终在DDPM中,均值μ的定义为
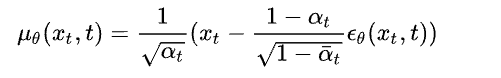
在DDPM中,逆向过程中的高斯分布的方差项采用的是一个常数项。
Guided Diffusion - 基于类别引导的扩散模型
类似于conditional-GAN,对于通用图像生成任务,加入类别条件能够比无类别条件生成获得更好的效果。因为加入类别条件的时候,实际上是大大减少了生成时的多样性。OpenAI的Guided Diffusion提出一种简单有效的类别引导的扩散模型生成方式。
Guided Diffusion的核心思想是在逆向过程的每一步,用一个分类网络对生成的图片进行分类,再基于分类分数和目标类别之间的交叉熵损失计算梯度,用梯度引导下一步的生成采样。这个方法一个很大的优点是,不需要重新训练扩散模型,只需要在前馈时加入引导既能实现相应的生成效果。
基于条件的逆向过程
在DDPM中,无条件的逆向过程可以用 pθ(xt-1|xt) 来描述,在加入类别条件y后,逆向过程可以表示为
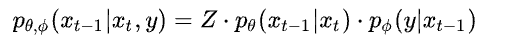
这里Z是常量。这个公式表示的意思是,基于类别条件的逆向过程,可以由无条件的逆向过程结合生成结果的分类损失来度量,此处 pΦ(y|xt-1) 表明的即是一个单独训练的分类模型。最终在guided diffusion 中采用的每一步逆向过程可以用以下式子描述:
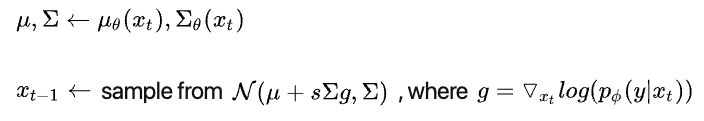
这里s是一个常量。在每一步过程中,在计算高斯分布的均值时加上方差和分类梯度项的乘积。基于这样的改进,不需要重新训练扩散模型,只需要额外训练一个分离器,就能够有效地在添加类别引导。该结构存在的一点小问题是会引入额外的计算时间(每一步都要过分类模型并求梯度)。这个问题在no-classifier guidence中有所改进。总的来说,扩散模型由于每一次逆向过程都要过至少一遍网络,所以总体生成速度通常还是比较慢的。
扩散模型结构改进
Guided Diffusion中,对DDPM中采用的U-Net结构进行了相关的优化调整:
- 在保持模型大小相对一致的情况下增加网络的深度与宽度。
- 增加attention-head的数量。
- 在 32×32、16×16 和 8×8 分辨率而不是仅在 16×16 分辨率下使用attention机制
- 使用BigGAN中残差块对激活进行上采样和下采样。
- Adaptive Group Normalization(AdaGN)的归一化模块
Disco Diffusion
在Guided Diffusion 中,每一步逆向过程里通过引入朝向目标类别的梯度信息,来实现针对性的生成。这个过程和基于优化的图像生成算法非常相似。也就意味着之前很多基于优化的图像生成算法都可以迁移到扩散模型上。我们可以通过修改Guided Diffusion中的条件类型,来实现更加丰富有趣的扩散生成效果。
这里介绍的Disco Diffusion是借鉴了另外一篇GAN的工作,VQGAN+CLIP,该工作利用CLIP作为损失函数的一部分,让VQGAN生成带目标文字语义的图片。
文本引导
CLIP(Contrastive Language-Image Pre-Training)是一个在各种 图像、文本 pair对上训练的神经网络。CLIP 模型包含一个图像编码网络EI(x)和文本编码网络 EL(l) ,两个编码网络能够各自将文本和图片编码为1*512 大小的向量,然后我们可以通过余弦距离来度量两者之间的相似度。
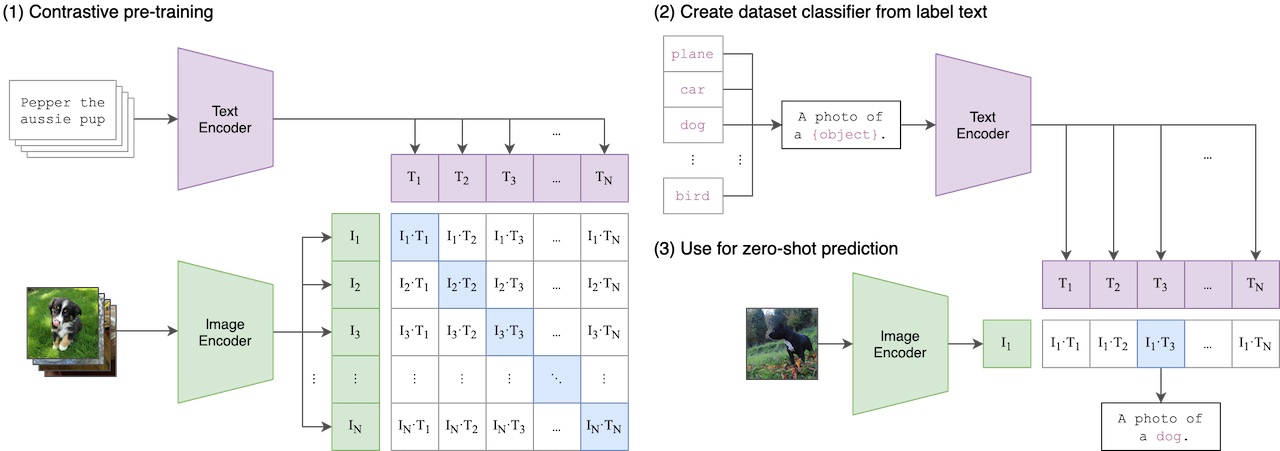
基于文本条件的图像生成中,就可以利用CLIP来度量一张图片是否和文本描述符合。