这一篇关于 Animate Anyone 的读书笔记。Animate Anyone介绍了一种能够根据图像以及结合动作姿态序列生成一段动作视频的方法。
方法结构图
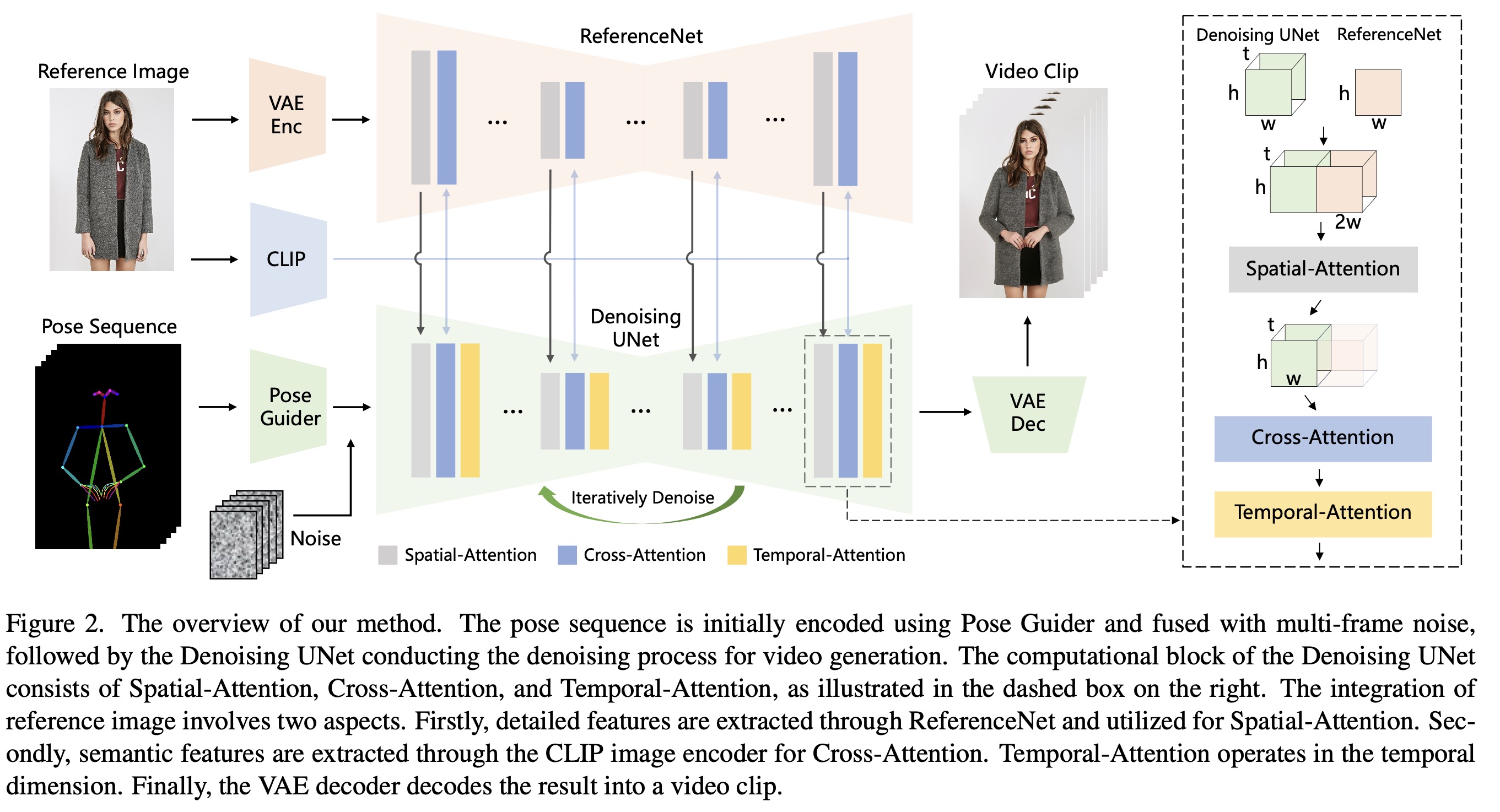
方法归纳为以下点:
- 整体方案是基于StableDiffusion。其中视频生成部分的借鉴了animatediff中的temporal attention的思路。
- 方案包含了三个主要组成部分:
- ReferenceNet - 目的是对reference 图片做encoding,得到图片的外表feature。
- Pose Guider - 对动作信号进行编码,来达到控制reference image动作的目的。
- Temporal Layer - 时序层,目的是为了让同batch生成的不同frame之间具备连续性。
ReferenceNet
设计ReferenceNet来提取图片的信息,而不是直接利用CLIP的原因是
- CLIP 的 image encoding 部分是基于224x224的分辨率训练的,这会导致encoding的feature 丢失了很多细节。
- CLIP是对比学习,CLIP image encoding学习出来的feature是为了匹配与之相对应的文本的encoding,这也会导致有一部分的细节会被丢失。
关于 ReferenceNet 的细节:
- ReferenceNet 权重是继承自SD。
- 用Spatial-attention layer 代替 Self-attention layer。具体来说如上图右上角的虚线框内部
$x_1∈R ^{t×h×w×c}$ 为UNet的 denoise feature map,$x_2∈R^{h×w×c}$ 为 referencenet 提取的图片feature map,把 $x_2$ 拷贝 t 次,然后沿着 $w$ 维进行 concatenate. 然后做 self-attention 后,取前半部分的feature。
- cross-attention部分使用的是CLIP image encoder。CLIP image encoder 语义空间和 CLIP text embedding 一致,但可以提供reference image 的特征,有助于加速网络训练收敛。
Pose Guider
为了减轻controlnet带来的计算量,设计了一个轻量级的Pose Guider。Pose Guider 由4层conv组成(4x4 kernels, 2x2 strides, 16,32,64,128 channels)。对pose图进行encoding之后和 latent noise 相加送到 Unet 网络。
Temporal Layer
借鉴了animatediff的方法
训练部分
首先训练分成两个部分:
- first stage:使用视频的单帧图片,这个阶段我们排除掉 UNet 中的 temporal layer,同时训练ReferenceNet 和 Pose Guider 两个部分。
- second stage: 把 temporal layer加回来,temporal layer部分的利用预训练的animateidff模型权重,结合视频帧数据(每次24帧)进行训练。
训练的细节:
- 训练用了 4 x A100
- 5K character video clips (2-10 seconds long)
- 第一个阶段,数据是从视频中抽帧,分辨率为768x768, center-croped,训练 3万个step, batch size是 64。
- 第二个阶段,数据是视频连续帧,每次24帧,batch size为4, 训练 1万个step。
结果

结果看起来还不错。
Limitations
- 模型的手部运动生成的结果不是特别稳定,有时会出现扭曲和运动模糊。
- 生成动作中如果角色需要生成原图中不可见的部分,效果会不太稳定,出现诸如模型和生成结果不自然等问题。
- 因为采用的是DDPM模型,所以生成效率上比非DDPM方案要差。