OpenAI 于2024.2.16 发布了视频生成模型Sora,Sora可以生成时长1分钟的高清视频,其生成质量非常惊人。
Demo:
https://cdn.openai.com/tmp/s/title_0.mp4
官网地址:Sora
技术报告:Video generation models as world simulators
简要信息:
根据OpenAI发布的技术报告,我们大致可以得到以下信息:
- Sora 的技术框是:Latent Diffusion Model (Stable Diffusion) 和 Diffusion Transformer (DiT) 的结合。
- Sora 可以生成 1分钟的高清视频,视频的分辨率,宽高比不受限制。
- Sora 生成的视频一致性非常好,并且兼容图像生成,图生视频,和视频续写的能力。
- Sora 的训练视频数据利用了 DALLE-3 中的 re-caption 模型来label视频帧信息。
技术框架部分:
LDM : Latent Diffusion Model
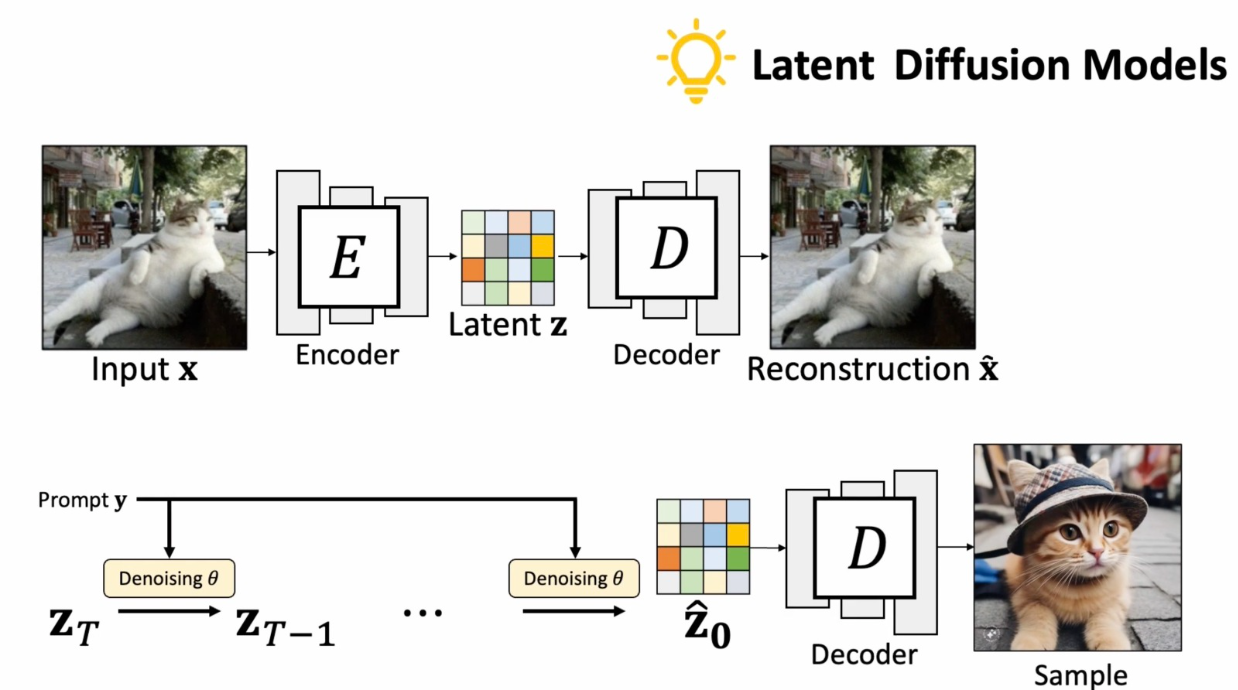
LDM 网络主要有三部分组成:VAE Encoder/Decoder, Unet denoise,以及 Condition 部分。Sora 这里主要借鉴的是 VAE Encoder/Decoder,把视频帧利用VAE encoder 压缩到一个更小的空间来减小计算量。
Sora 技术报告中的 latent 处理:
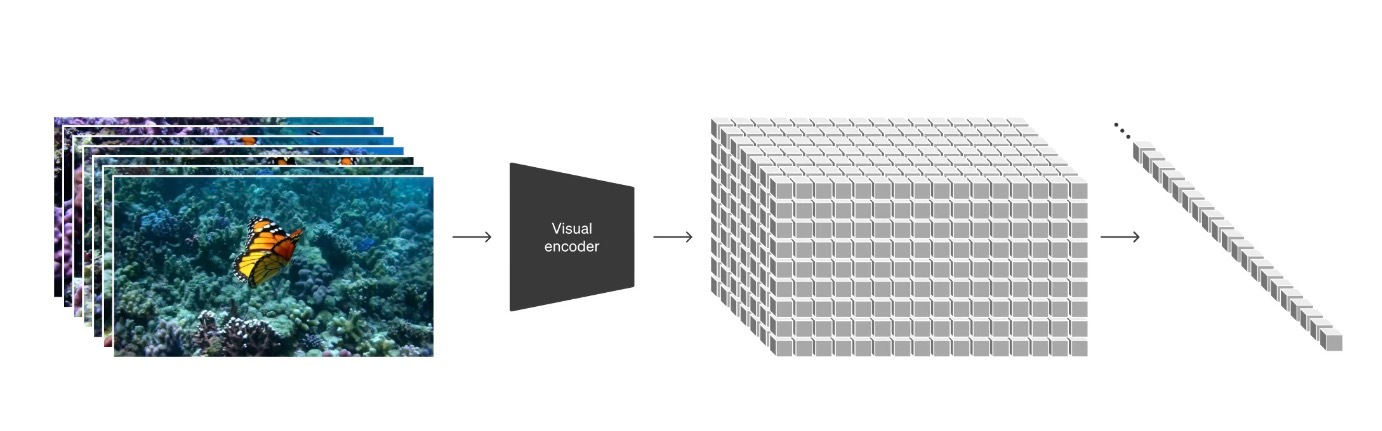
对一组视频帧先进行 Visual encoder 得到每一帧对应的 latent code,然后把latent code patchy 成一维序列化数据。
DiT:Scalable Diffusion Models with Transformers
根据LLM中的经验 transformer 架构的网络可扩展性更强,在 LLM 中,增大 transformer 模型的参数量,性能会可预期的得到提升。DiT 证明了可以用 transformers 架构代替之前 Diffusion 模型中的 UNet 网络来完成 denoise 的能力。Sora 的技术报告中 reference了DiT。
DiT:[2212.09748] Scalable Diffusion Models with Transformers
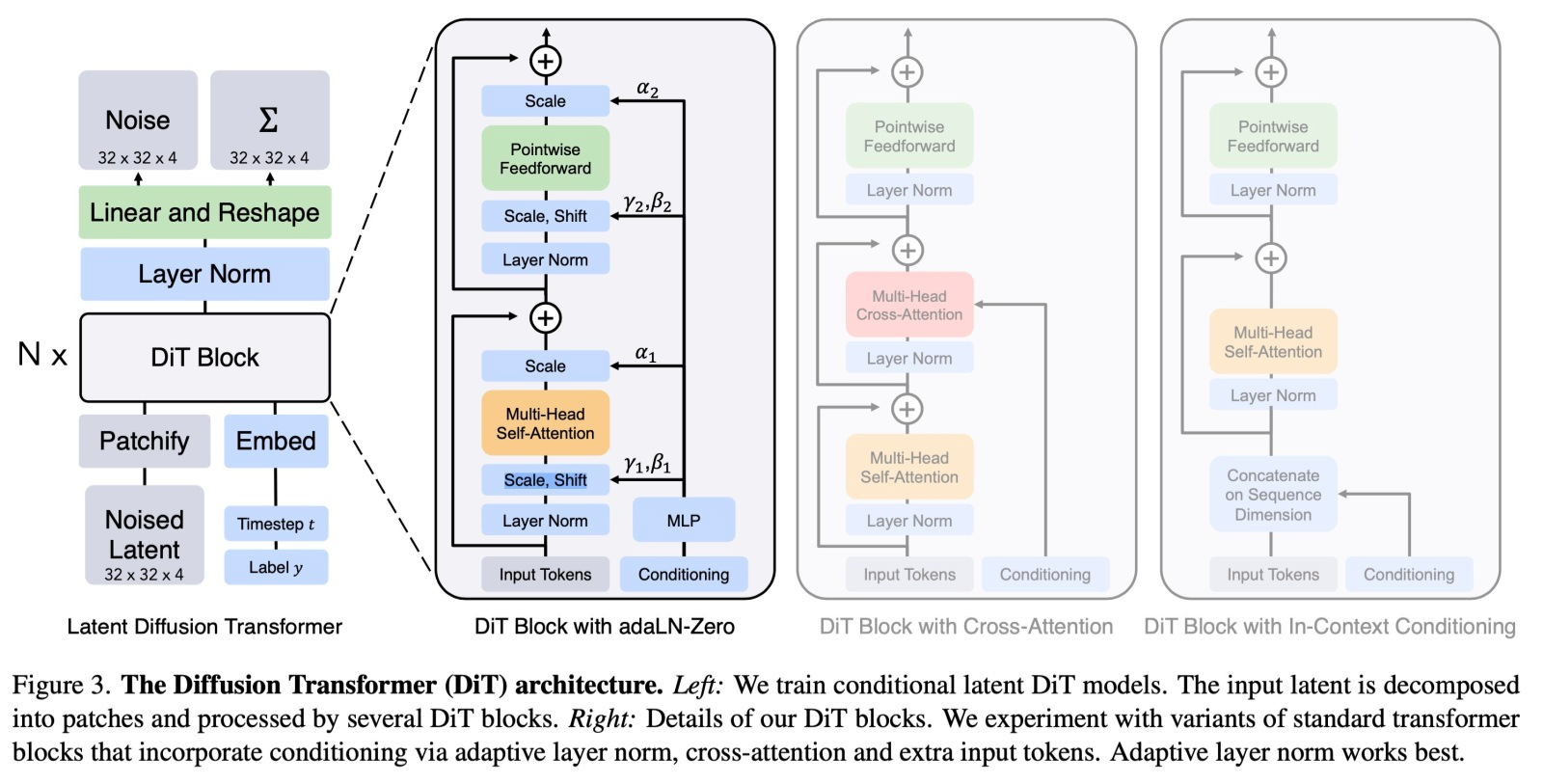
DiT 网络上图展示的是比较清晰的,其结构是一个典型的 Transformer 结构,需要注意的有两点:
- 网络的输入为一维数组。
- DiT 网络的 condition 是 class label,而非文本。
DiT 网络为纯 Transformer 架构的网络,它只能处理输入为一维的数组。所以这里对这一组 latent code 进行 Patchify 操作,把2维数据 reshape 成 1维数据。
Patch的具体操作,如下图:
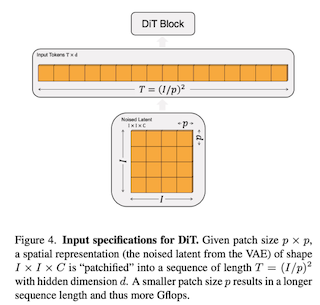
因为 Sora 处理的是视频数据,所以 Sora 这里最后得到的一维数据(Tokens)的长度是 $(I/p)^3$。
💡 ViT 结构的视觉模型,对图像进行 Patch 完成二维数据转换成一维序列化数据之后,会对序列化数据加一个位置编码来标记每一个Token对应在原图片的位置。如下图所示:
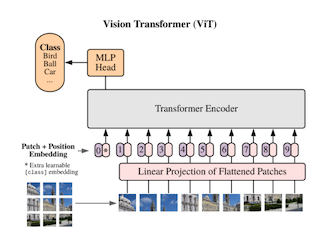
Sora 处理的是视频数据,OpenAI 的技术报告中并没有说明如何对3维数据转换成一维序列化数据之后,位置编码是如何操作的。一个猜测是每一帧视频上面的小 patch,它的位置信息被定义成 (x, y, t): x, y 表空间位置关系,t 表视频帧的时间信息。
class label 变为文本:
这部分 Sora 没有提及如何做的,DiT 论文也没有这部分内容,可以参考的是[2310.00426] PixArt-$α$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
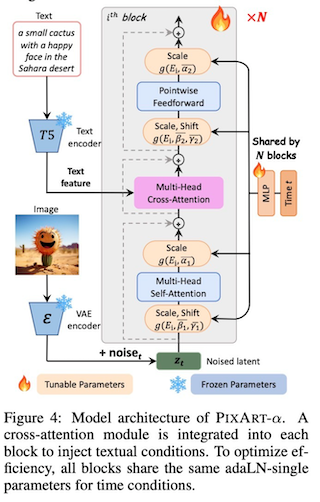
不同于 DiT 中利用 AdaLN 来插入 condtion 信息,PixArt 利用的是类似 Cross-Attention 来对齐模型生成内容和文本。
不过即便理解了 LDM 和 DiT 之后,但还是无法解答 Sora 是如何让生成的视频主体一致性如此高。
数据部分
Sora 使用了 DALL·E 3 中 的 re-caption 能力,来对训练的视频关键帧进行label。
根据 Sora 的技术报告描述,利用图片的 caption 模型来对视频进行caption,前提是图片的caption信息能覆盖视频的主要信息。这要求训练视频,它的场景需要是单一的,不能有场景切换。Sora 没有对视频数据的来源做任何的公开
扩展应用
Sora 可以看做是一个通用型的视觉生成模型,它还可以完成:
-
1. 图像生成,Sora 可以生成分辨率最高达 2048x2048
-
2. 图像/视频续写
-
3. 视频混合,给到两段视频,利用 Sora 让两段视频融合成一段视频,官网上的效果非常惊人。
[https://cdn.openai.com/tmp/s/prompting_7.mp4]
此外,官网还展示 Sora 在 3D一致性,长窗口主体一致性上的惊人表现。
小结和思考
-
1. Sora 的最大的贡献是:
-
a. 把视频的生成上限提到了一个让人惊叹的高度。其视频生成效果远超目前其他工作。单帧的生成细节,视频的帧间连续性和稳定性都非常好。
-
b. 把 Transformer 和 Diffusion 两个工作结合起来,虽然 Sora 不是第一个提出可以这样结合,但是却是第一个让两者结合做出如此惊人效果的工作。
-
-
2. 疑问,以下是一些很重要,但是技术报告中没有提及的:
-
a. 训练的视频数据的来源,数据的量级,规格(清晰度,视频长短),以及文本是如何标注的。
-
b. Diffusion模型我们知道用了transformer,但模型的大小,模型的具体结构并不清楚。以及用来提取文本信息的语言模型用的是什么模型,也不清楚。
-
c. 其视频生成如何做到如此的高质量,以及长窗口情况下主体的一致性能做到如此的好,这个难度非同一般,不是简单的一句用了 transformer+diffusion 的结构就能解释的。
-
d. 具体到输入部分的处理,单个patch的位置是如何编码的,视频帧的latent code flatten 成 tokens之后,如何保持单帧上patch的位置关系,以及多帧之间的连续性相关性的?
-