本文主要介绍 Google 最新的一篇关于如何把 diffusion 模型 port 到移动端设备上的论文 MobileDiffusion: Subsecond Text-to-Image Generation on Mobile Devices。google 的博客上有相关的英文blog:https://blog.research.google/2024/01/mobilediffusion-rapid-text-to-image.html。本文主要是对这篇blog进行了翻译,以及放了一些paper中信息。
文生图模型发展非常迅速,diffusion 模型展现出了非常卓越的图像生成能力。主流的文生图扩散模型:Stable Diffusion, DALL-E 2, Imagen 生成质量都很好,但是其模型参数量大,单图运行时间长,导致无论是模型大小,还是耗时都很难在移动端设备上有效运行。
如果能把文生图扩散模型部署到移动设备上,其好处有:
- 用户不需要联网在云端生成图片,其隐私会好很多。
- 考虑到云端GPU的资源也有限,手机端直接运行可以有效减少用户的等待时间,提升用户体验,让用户更有效率。
本文提出了一个新的模型:MobileDiffusion,其旨在解决Diffusion模型无法运行在移动端上的问题。
Mobiel Diffusion 模型参数量仅为 520M,在主流手机设备上生成一张512x512的图片,耗时在半秒以内。
背景
把文生图扩散模型移植到移动端设备上会遇到两个主要问题:
- 文生图扩散模型在生成图片时需多次迭代(DPM ~20steps)去噪才能生成高质量的图片。
- 文生图扩散模型的网络参数量很大,通常达到了数十亿级别;这种大小的神经网络,无论是存储还是计算,对移动设备来说都是不小的挑战。
优化扩散模型前向时间是一个非常活跃的领域。对于上述第一个问题,即如何减少迭代次数,业内已经进行了广泛的研究。目前已经有一些新的技术被应用,比如更好的 SDE solvers(例如 DPM)和蒸馏技术(例如 progressive distillation 和 consistency distillation)。利用这些新技术,可以将扩散模型的前向步骤从数百步减少到个位数。而最近的一些技术,如 DiffusionGAN 和对抗扩散蒸馏,甚至可以将前向步骤减少到一步。
而文生图扩散模型本身的网络结构,其得到的关注和有效优化会少一些。
Mobile Diffusion
Mobile Diffusion 是在 Stable Diffusion 的基础上进行了相关的改进。它由三个部分组成:文本编码器,扩散网络UNet,图片解码器。其中 文本编码器,本文采用的是 CLIP-ViT/L14,它的模型参数量为 124 M,对移动设备比较友好。
Diffusion UNet
文生图扩散模型UNet网络主要是由 transformer blocks 和 convolution blocks组成。其中 transformer block 由self-attention layer, cross-attention layer 以及 feed-forward layer 三个部分组成。
- self-attention layer 用来建模视觉特征之间相互的远程依赖性。
- cross-attention layer 用来让文本condition和视觉特征相互作用
- feed-forward 用来对 attention 层进行后处理
tranformer block是网络中最关键的部分,对生成图片语义是否对齐文本起到决定性的作用。不过 attention 操作的计算复杂度是序列长度的二次方,会带来很大的效率挑战。本文遵循 UViT 结构,在UNet的bottlnet部分放更多的transfomer block。
MobileDiffusion 的UNet 架构在高分辨率部分不用 SA,并在网络的中间部分加了更多的transformer blocks.(其实和SDXL 的网络优化有点类似)。

网络中的 conv blocks,用于提取特征,其计算成本,特别是在高分辨率的layer,还是比较大的。 MobileDiffusion 使用了 MobileNet 的深度可分离卷积,在UNet 比较深的部分使用轻量级可分离卷积层代替常规卷积层,以此来减少网络的计算量。
下图是MobileDiffusion 和 其他模型关于 FLOPs(浮点运算量)和网络参数的对比。
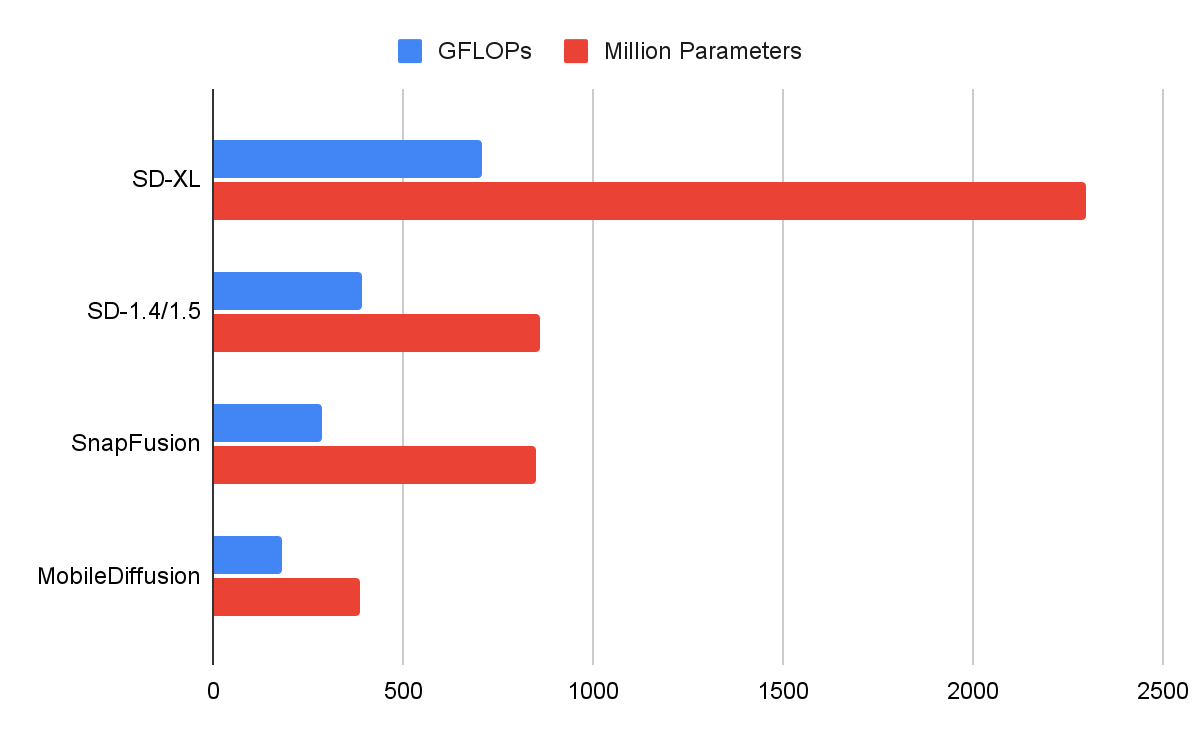
Image Decoder
本文训练了一个 VAE,和SD的VAE不同的地方是,本文的VAE 把一张RGB图片编码到一个大小为 1/8, channel 为8 的 latent code。(SD的VAE 的channel数为4)。
下图是关于 VAE 重建能力的对比

下面的表格是关于 VAE 的量化指标:
| Decoder | #Params (M) | PSNR↑ | SSIM↑ | LPIPS↓ |
|---|---|---|---|---|
| SD | 49.5 | 26.7 | 0.76 | 0.037 |
| Ours | 39.3 | 30.0 | 0.83 | 0.032 |
| Ours-Lite | 9.8 | 30.2 | 0.84 | 0.032 |
One-step sampling
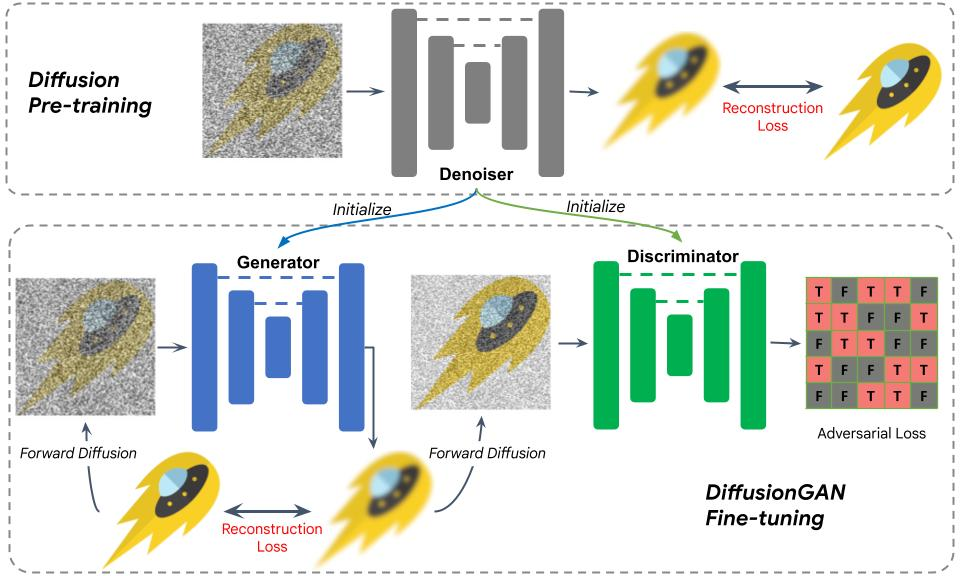
为了优化扩散模型生成过程的迭代步数,本文引入了 DiffusionGAN 的方法。考虑到从头训练一个DiffusionGAN,难度大,训练成本高。本文利用预训练扩散模型来初始化GAN网络的 generator和discriminator,这种策略显著简化了训练。
下图是关于 DiffusionGAN 的训练处理细节。经过初始化之后,一张噪声图片被送到generator中,经过一次diffusion,其结果output被用来和groundtruth进行重建loss计算。
然后对output进行加噪声,并送入到判别器中,进行GAN loss计算。因为使用了预训练的模型权重来初始化生成器和判别器,训变成了一个finetune过程,模型经过不到10k的迭代就收敛了。
Results

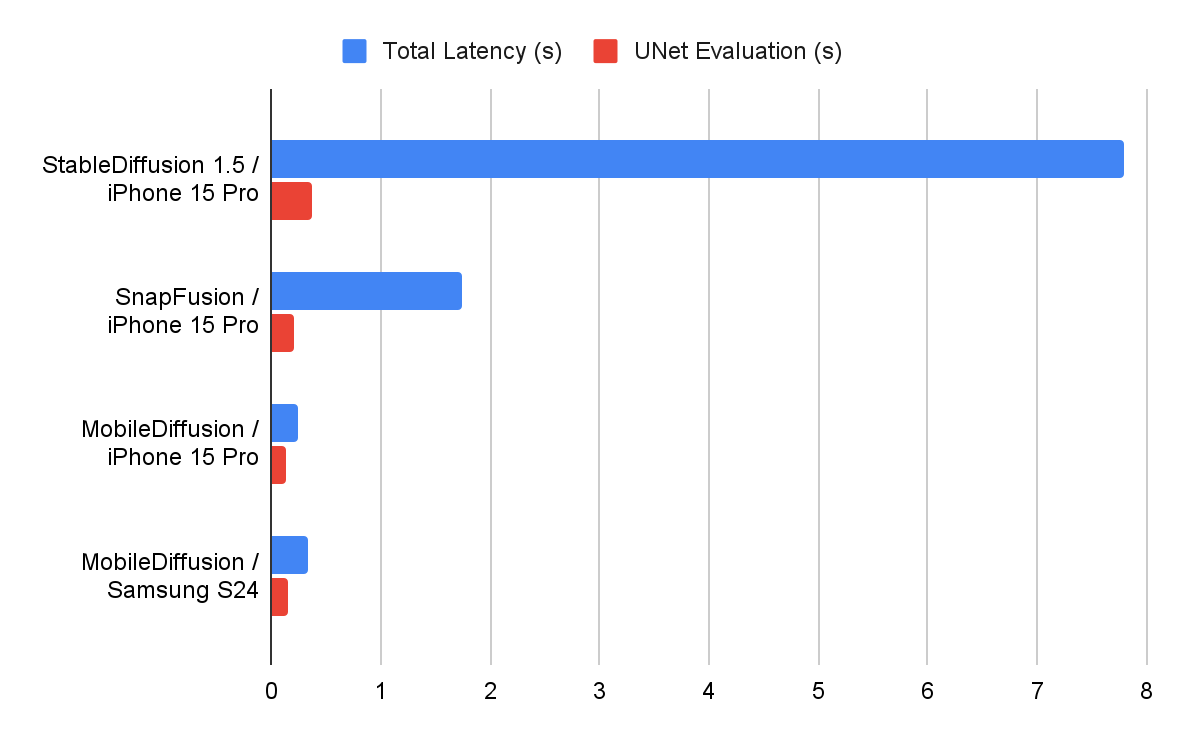
耗时对比
以上。