这是一篇译文,原文Review: FCN (Semantic Segmentation))
本文主要记录用于语义分割的全卷积网络。和分类,检测任务相比,分割是更难的一种任务。
- 图片分类:对图像进行分类
- 物体检测:检测一张图片中存在的物体,并给出物体的区域。
- 分割:为图像中的每个像素分类。
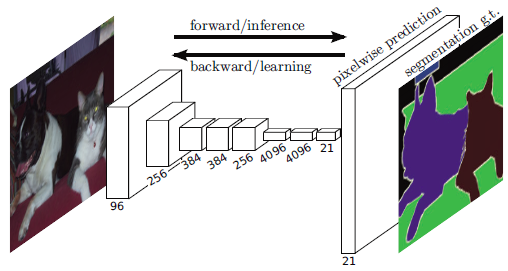
一个语义分割的例子:

该论文发表于 2015 CVPR,现在有 6000 次引用。它也是使用FCN进行语义分割的最基础的论文之一。
本文包括
- 从图像分类到语义分割
- 利用反卷积进行上采样
- 融合输出
- 结论
1.从图像分类到语义分割
传统意义上的分类任务,输入图像会缩小尺寸,并通过卷积层和全连接层,最终输出关于输入图片的标签,如下图:
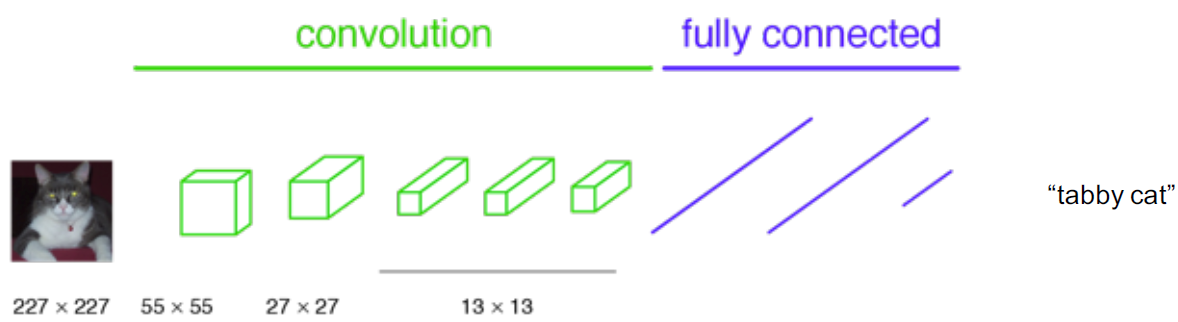
想象我们把上图中的全连接层替换成 1X1 卷积层:
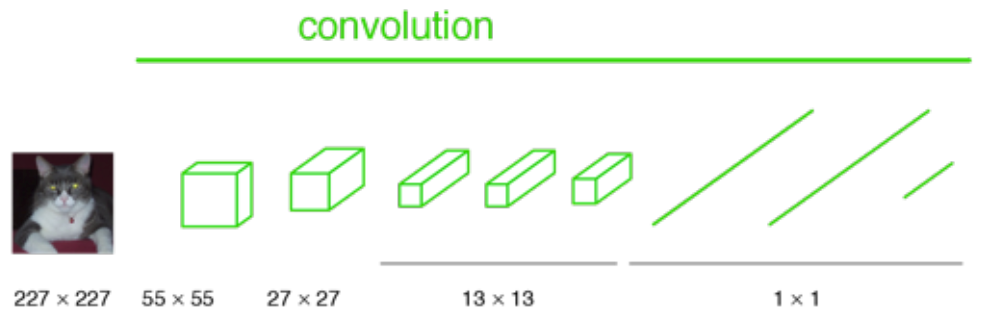
如果图像没有缩小尺寸,输出将不是单个标签。相反,输出的大小小于输入图像(由于最大池化层)
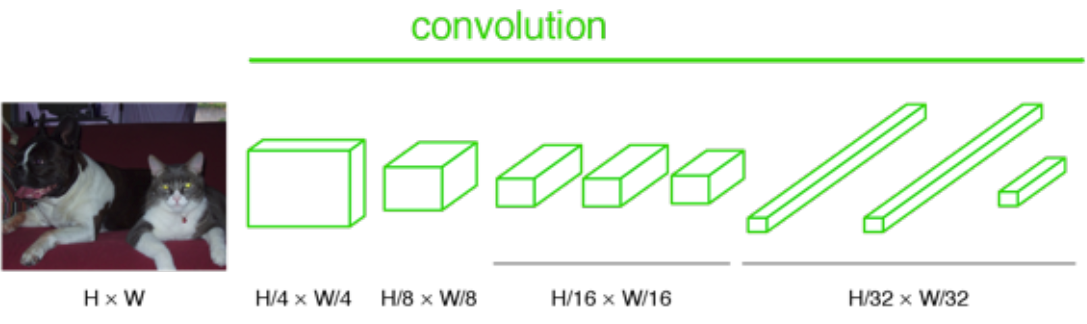
如果我们对上面的输出进行上采样,那么我们逐像素输出标签贴图,如下所示:
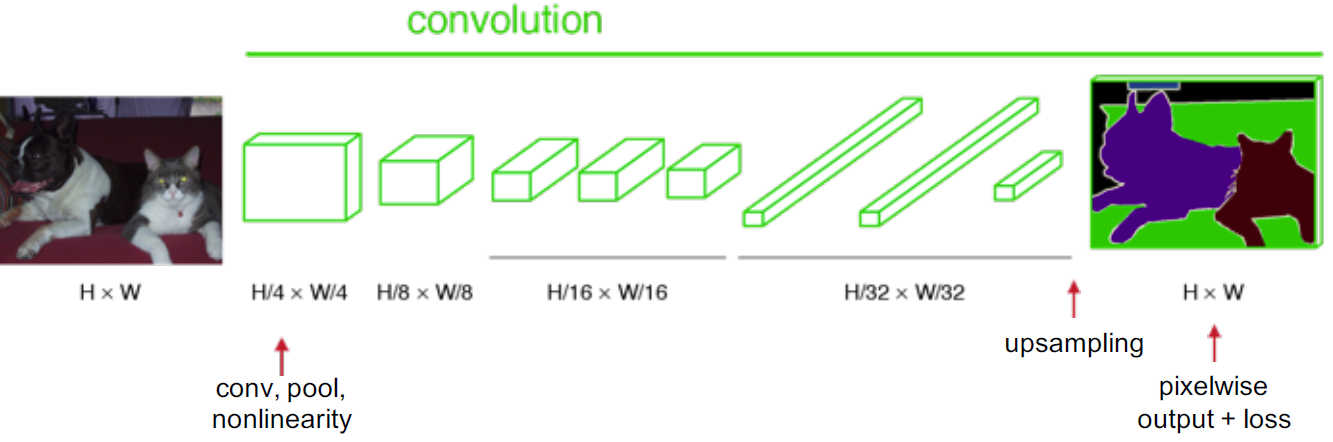
2.利用反卷积进行上采样
卷积是一个使输出尺寸变小的过程。反卷积就是一上采样,使得输出尺寸变大的过程(但不要把反卷积曲解成卷积的逆向操作),反卷积也被称为上卷积和转置卷积。当使用分数步幅时,也被称为分数步幅卷积。
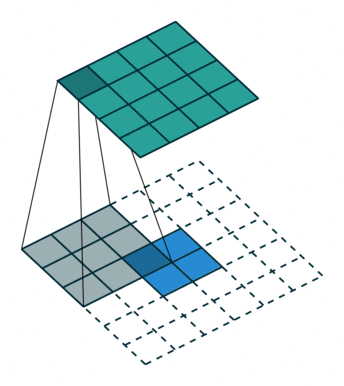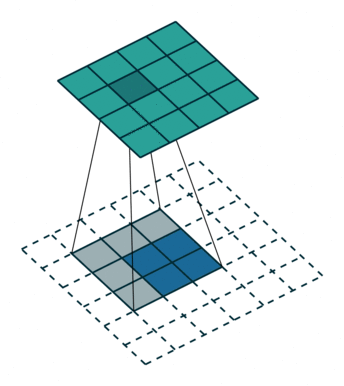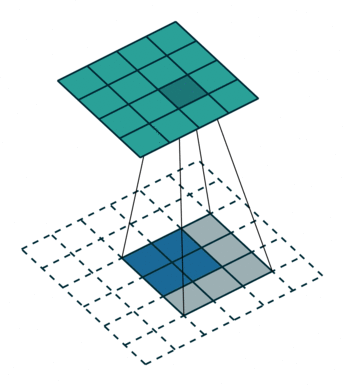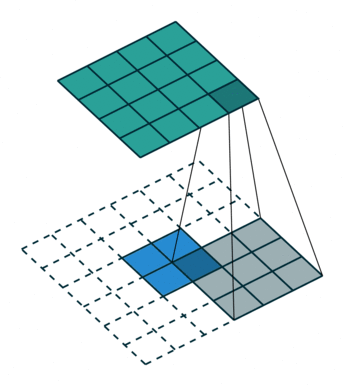
3.融合输出
经过如下图所示的conv7后,输出尺寸很小,然后进行32X 上采样,得到和输入同样大小的输出。但也会把输出标签变得很糙。这个叫 FCN-32s:

这是因为在网络变深的时候能够获得深层次的特征,但如此同时空间位置信息也会丢失。这意味着浅网络可以获得更多的位置信息。如果我们把两种网络合并在一起,我们可以平衡结果。
为了组合,我们融合输出(通过元素添加):
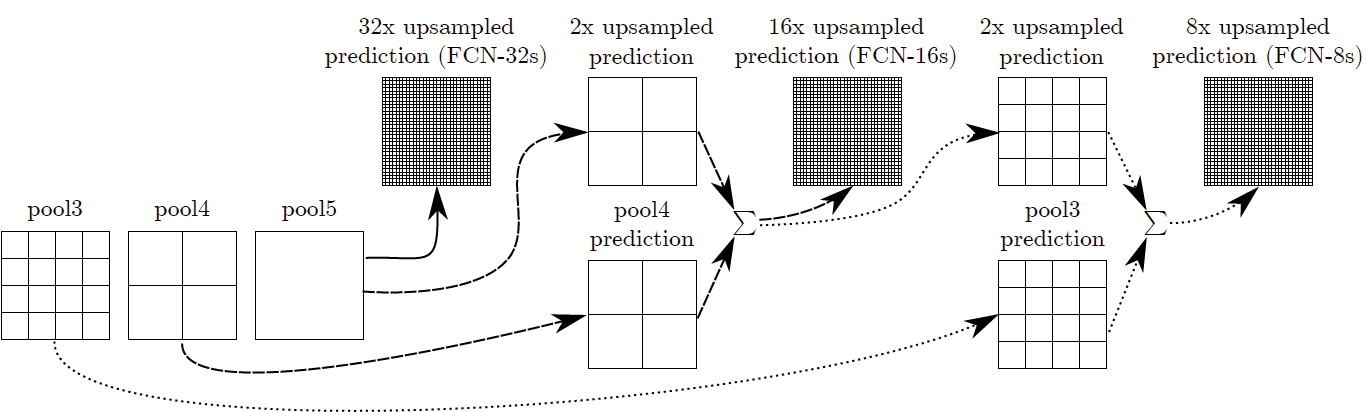
**FCN-16s:**的输出是把pool5的输出2倍上采样和pool4融合并进行16次上采样。**FCN-8s:**操作如上图所示,也是类似。
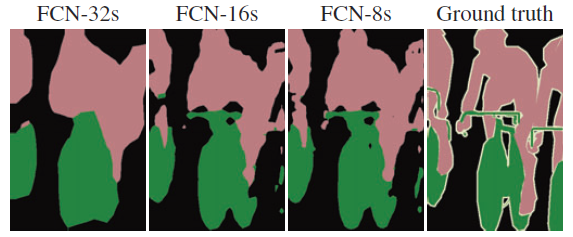
FCN-32s由于位置信息丢失结果非常粗糙,而FCN-8s的结果最好。
这种融合操作实际上就像AlexNet,VGGNet和GoogleNet中使用的增强/整合技术一样,它们通过多个模型结果的叠加,使预测更准确。但在这个任务中,它是针对每个像素去做的,并且它是拿模型中不同层的结果去叠加的。
4.结果

- FCN-8s在Pascal VOC 2011数据集上效果最佳
- FCN-16s在NYUDv2数据集上效果最佳
- FCN-16s在SIFT数据集上效果最佳

第四行显示了一个失败案例:网络把船上的救生衣当作了人。
希望将来能够更多地阅读有关语义分割的深度学习技术。
References
- [2015 CVPR] [FCN] Fully Convolutional Networks for Semantic Segmentation
- [2017 TPAMI] [FCN] Fully Convolutional Networks for Semantic Segmentation