主页: EMO
简介:
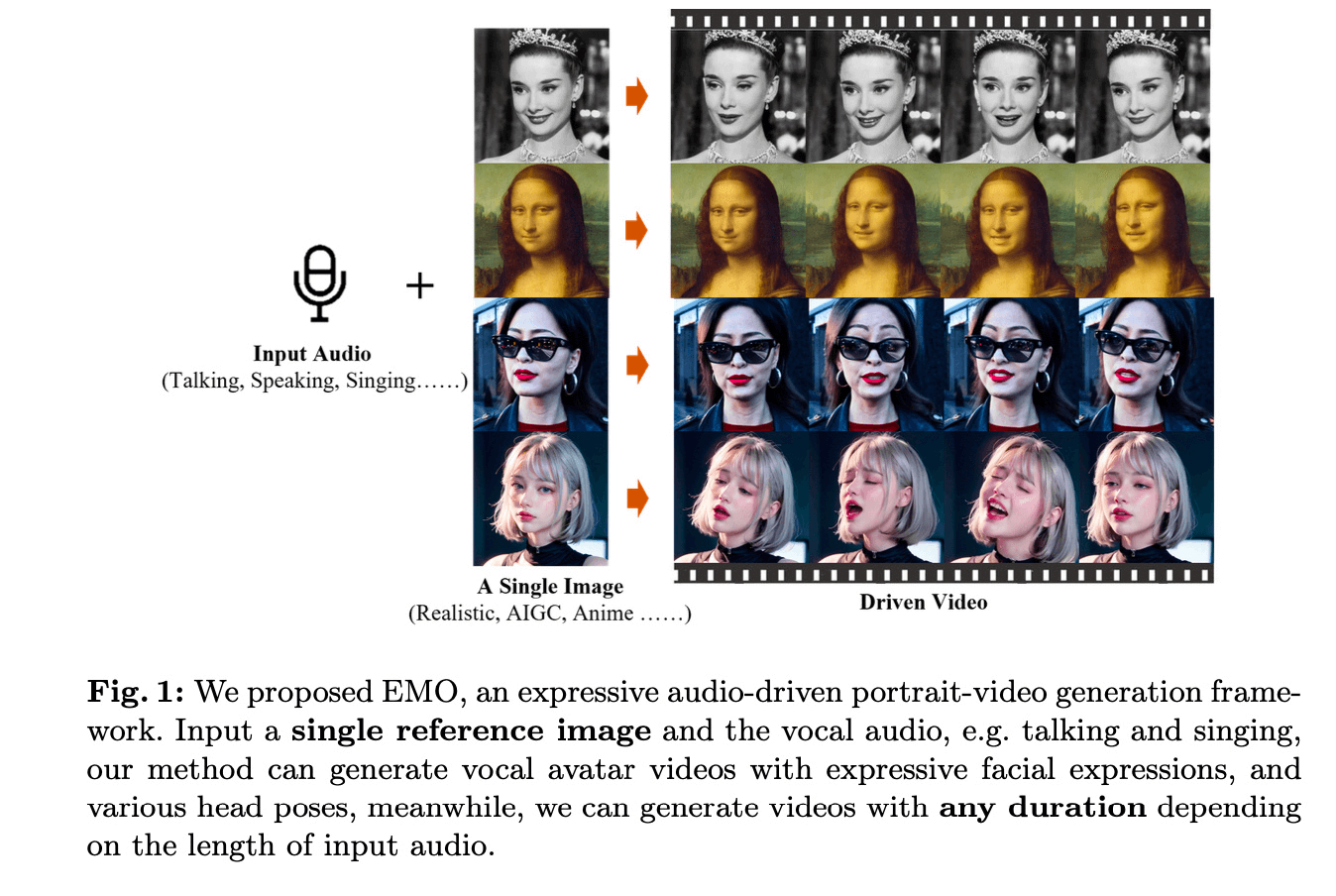
阿里最新的一片 talking head 的工作,输入为一张 reference image 和 一段音频,生成一段视频。EMO 这篇工作生成的视频结果,其视频生成结果稳定,帧间一致性强,生成质量好,特别是它脸部表情的生成非常丰富。
数据集:
公开数据集:
VFHQVFHQ : 16,000 high-fidelity clips of diverse interview scenarios. 但是这些视频没有audio,论文中只用于第一阶段训练。
数据量级:
250小时的视频,以及160M的图片,并且要保证 视频和图片的多样性。
方法:
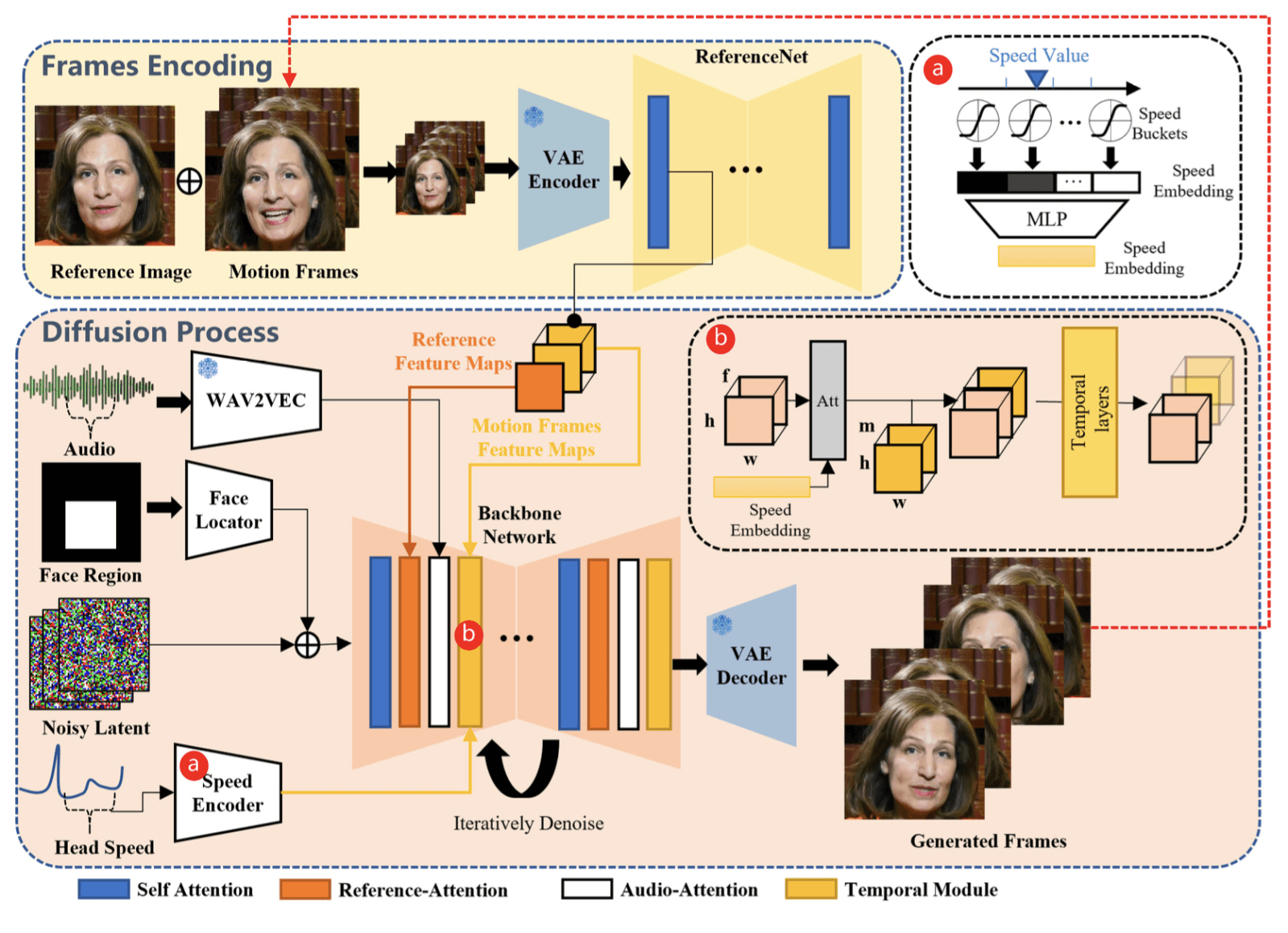
网络整体框架是基于SD1.5,由五个模块组成:基于SD的Backbone Network,ReferenceNet, Audio layers,Control signal 以及 input 部分。
- 基于SD的Backbone Network:
- SD的 cross attention,k,v 从之前的 text prompt 的 clip embedding 替换为 ReferenceNet 的 特征。
- temporal module: 结构借鉴 animatediff,模型初始化的 weights 为 animatediff 网络 weights。
- 关于如何做到 demo 中可以生成任意时长的视频:方法上是参考了 SparseCtrl, 简单来说就是用上一个 batch 的最后四帧,作为下一个 batch referenceNet 输入的一部分。具体来讲是:取当前 batch 生成结果的 last n frames (n = 4 ),用 referenceNet 提取这 n 帧的特征,然后在 UNet denoise 过程中,将这 last n frame 的 referenceNet feature 和 SD 主干网络的 hidden state 特征在 frame 维度上 concat(e.g. 16->19),concat 之后的特征作为 temporal attention 的输入,通过 attention 计算,让帧间信息进行传递,达到视频一致性的目的。
- ReferenceNet:
- referenceNet 的目的是为了让生成的视频保持住 ID 形象。 网络结构 和 SD 的 UNet 一致。
- 前向的时候,输入的用户图经过 referenceNet 提取特征,特征和 SD 主干网络 的特征 concat 后进行 Attention 操作。
- Audio layers:
- 利用 WAV2VEC 提取 audio 的特征。
- 考虑到生成结果需要参考上下文信息,所以会对每帧 embedding concat 当前帧音频的前后m帧信息,这样形成了一整个embedding插入到主网络中(在每个ref-attention后增加了cross attention layer)
- 不过这里有个疑问是,音频部分concate 前后 m 帧音频信息,那和视频帧数据在训练的时候会有 mismatch 的问题,不清楚音频在前向的时候需要什么其他特别的处理。
- Control signal:
- FaceRegion 为生成人脸的区域,mask 通过一个 Face Locator(几层卷积)得到encoded mask;encoded mask 加到 noisy latent 上,来控制人脸生成的区域。
- Head Speed,根据6D-DOF提取视频人脸的欧拉角来计算人头移动的速度。
- 这部分按照论文里面的解释是为了解决生成结果人脸移动速度过于单一的问题。类似指的是在任何音频驱动下,人头的移动速度是相对固定的。这不太利于表现不同音频中的情绪。
- 为了解决这类问题,论文提出通过嵌入 Head Speed 来控制生成视频中的人头移动速度。实现方法有点参考 SVD 中的 motion strength。SVD 在训练的时候,通过光流网络对视频进行 motion 分组,视频变化剧烈的分到 motion strength 大的 bucket,视频变化小的就分到 motion strength 小的 bucket,并且在训练的时候,把 motion strength 通过类似 control 的形式注入到网络中,这样在前向的时候就可以通过调整 motion strength 的大小来有效控制生成视频的变化强度。
- 具体到EMO,论文中提出了利用头部欧拉角的变化来计算人头的移动速度,并将速度范围划分为 d 个离散速度bucket,每个bucket都定义为一个不同的velocity level,每个bucket都有一个中心值和半径,再经过一个公式将w进行rescale到有限区间,concat前后m帧值之后通过MLP映射成一个speedembedding,这个embedding经过repeat变换为和原feature map除了c以外一样的大小,通过crossattention插入,最后再为送入temporal layer做准备(送入temporal layer之前还有ref feature的插入)
- input 部分
- 输入noise latent 如 frame=12,在计算过程中需要在frame维度上concat last n frames feature 如 frame=4,最终输出维度frame=16。
训练分成三个阶段
- 第一阶段是:训练数据为的图片预训练阶段;第一阶段训练的模型为 Backbone Network(也就是SD 的 UNet 部分), ReferenceNet 和 Face Locator 部分。训练的数据为上述的150M 图片和视频帧。
- SD UNet 需要重新 finetune,而不是通过 Lora 或者其他 adaptor 的方式,可能的原因是因为这个方案在设计的时候,把 condition 输入从 text 改成了 reference image,这样 SD UNet 中 cross-attention 的 k,v 就完全变成另外一种模态的输入,需要重新训练。当然了,这里如果不想完全重新训练 SD UNet,可以考虑引入 IP-adapter 结构,训练量会少一些。
- 第二阶段是训练 temporal module ,训练中是联合 audio layers 一起训练,n+f contiguous frames(n frames are motion frames)其中 temporal 的部分由 animatediff 初始化。
- 第三个阶段加入了 speed layer,这个阶段只训练 temporal modules 和 speed layers。文章描述速度层和音频层的同时训练会破坏音频对角色动作的驱动能力(说明音频层是贡献驱动信号的重要部分);通过分阶段训练来解决音频和 head speed 之间耦合的问题。
综合来说, EMO 这个工作把 TalkingHead 这个领域的生成效果又抬到了一个新的阶段,他生成的视频最大的优点是人脸根据音频表现出来的表情丰富度,很细腻,质量也很高。
回归到算法上,EMO 算是在前人的工作上,把各种有效方法拿来进行组合封装,AnimateDiff 用来处理视频生成的consistency问题, ReferenceNet 用来处理保角色的问题。在 Diffusion 这类生成范式下,把效果做到了出类拔萃。
以上。