本文提出一个基于latent diffusion框架的文生图模型Emu;利用小量~2000张高质量图片,对pre-trained模型进行quality-finetune,可以显著提升模型生成图片的质量。
AutoEncoder:

Stable diffusion使用的autoencoder,latent code 的channel是4, 本文发现4 channel的AE在还原图片一些细节上还不够,emu使用的是16 channel的AE。
Text embedding方面,使用的是 CLIP ViT-L 和 T5-XXL
Diffusion模型 UNet 的参数量是2.8B,和SD v1.5差不多一个量级。
核心输出是数据部分,本文先准备了一个 1.1B 的text-image paired 数据集进行pretrained模型训练,然后利用人工进行高质量的筛选,得到了2000张图,对pretrianed的模型进行quality-finetune。
finetune 的 batchszie是64,< 15k 个iteration。文中也提到了这种小样本的finetune很容易造成overfiting和degradation。所以iteration也设置的比较小。
Metrcis方面,都没有传统的CLIP score和FID了,完全是 user- study。分为两个维度,分别是视觉效果,以及文本对齐。
测试集用的是 google 的 Parti论文中的测试集,以及OUI(our 2100 Open User Input Prompts)。
选择5名人员对结果进行盲测,盲测方法是给到Emu的结果,以及非Emu的结果,让用户选择 A,B或者差不多。
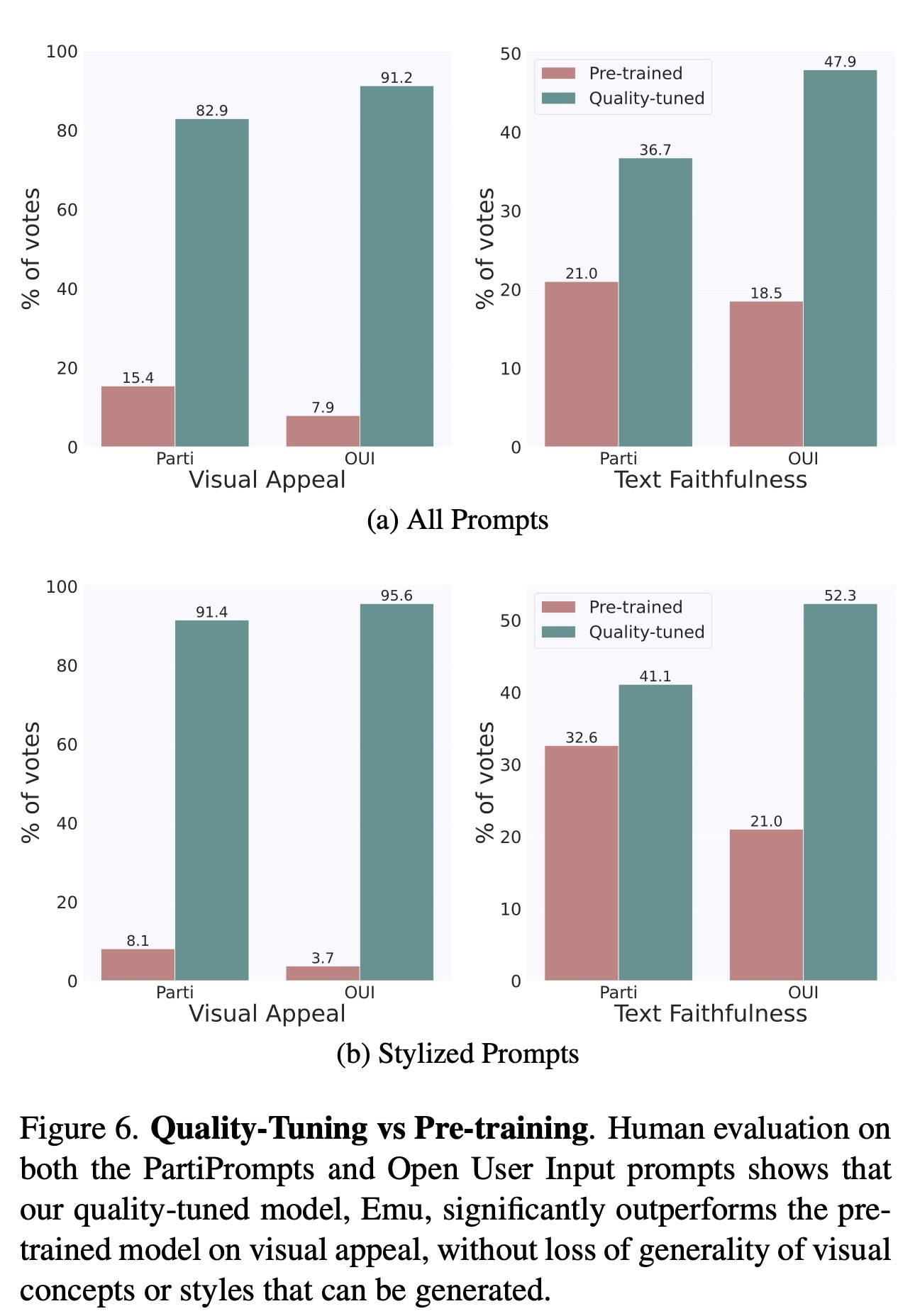
下面是Emu和pretrained的模型对比,看起来提升还是比较明显的。(但也不排除他们自己训练的pretrained的模型比较差)
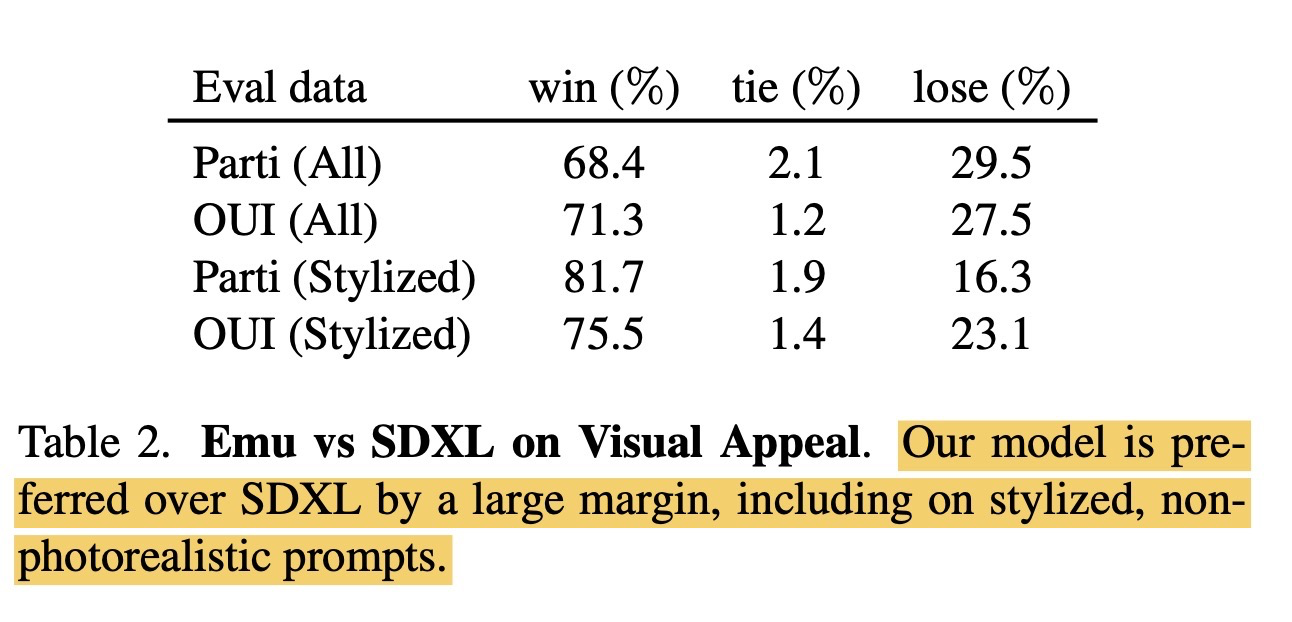
和SDXL对比,也会有一些优化
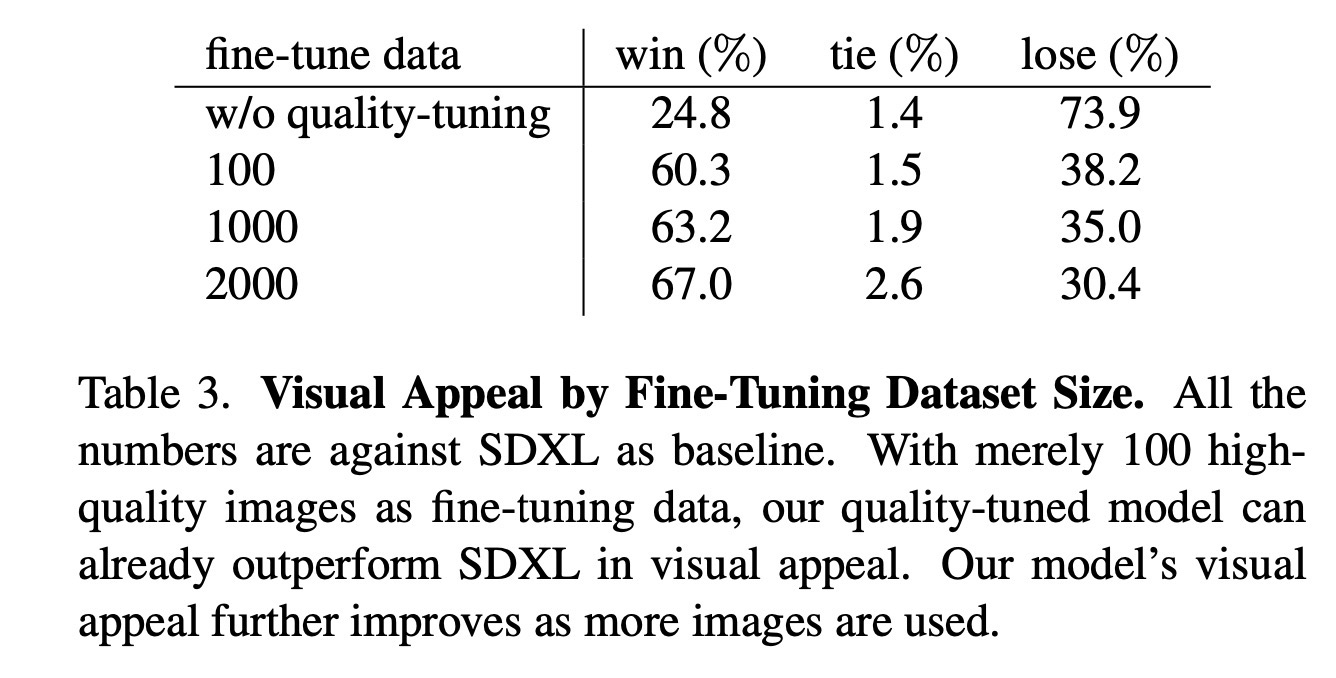
文中还做了不同数据集大小的带来的量化优化结果。可以看到100张图,就会给结果带来不小的提升。(不过这里要吐槽下,w/o qualitu-tuning果然比SDXL差了很多)
小结:
Meta在大模型上的开源贡献有目共睹,这一篇小样本finetune文生图,也值得关注。不过从文章本身来看,有效信息还是比较少。利用小一点的数据集进行finetune,这个在开源社区已经被很多人试验过,并给出了一些比较好的模型效果了。所以也不能算是什么大新闻。