这是一篇关于 https://arxiv.org/abs/2303.05511 的笔记。
近两年基于扩散概率模型和自回归模型的文生图大模型发展迅速。20,21年的SOTA生成网络GAN在这一波文生图大模型发展中缺失了。本文研究的问题是把GAN based 的模型放大,并利用目前文生图领域积累的 image-text 大数据,去训练 一个 GAN based 的文生图大模型 :GigaGAN。
GigaGAN 的参数量是 1B, 是 StyleGAN 的36倍,StyleGAN-XL 的 6倍。对比Stable Diffusion的参数量是 700M, Imagen: 3.0B, DALLE-2: 5.5B, Parti: 20B。 GigaGAN的参数量不算很大。
在1B参数量的情况下,由于GAN 的 sample 不是 Diffusion那种需要迭代多个 Step,sample的耗时上有一些优势:
sample 512 px 的 image 需要 0.13s (A100)
sample 4k (16-megapixel) 需要 3.66s
Giga 的 网络结构图:
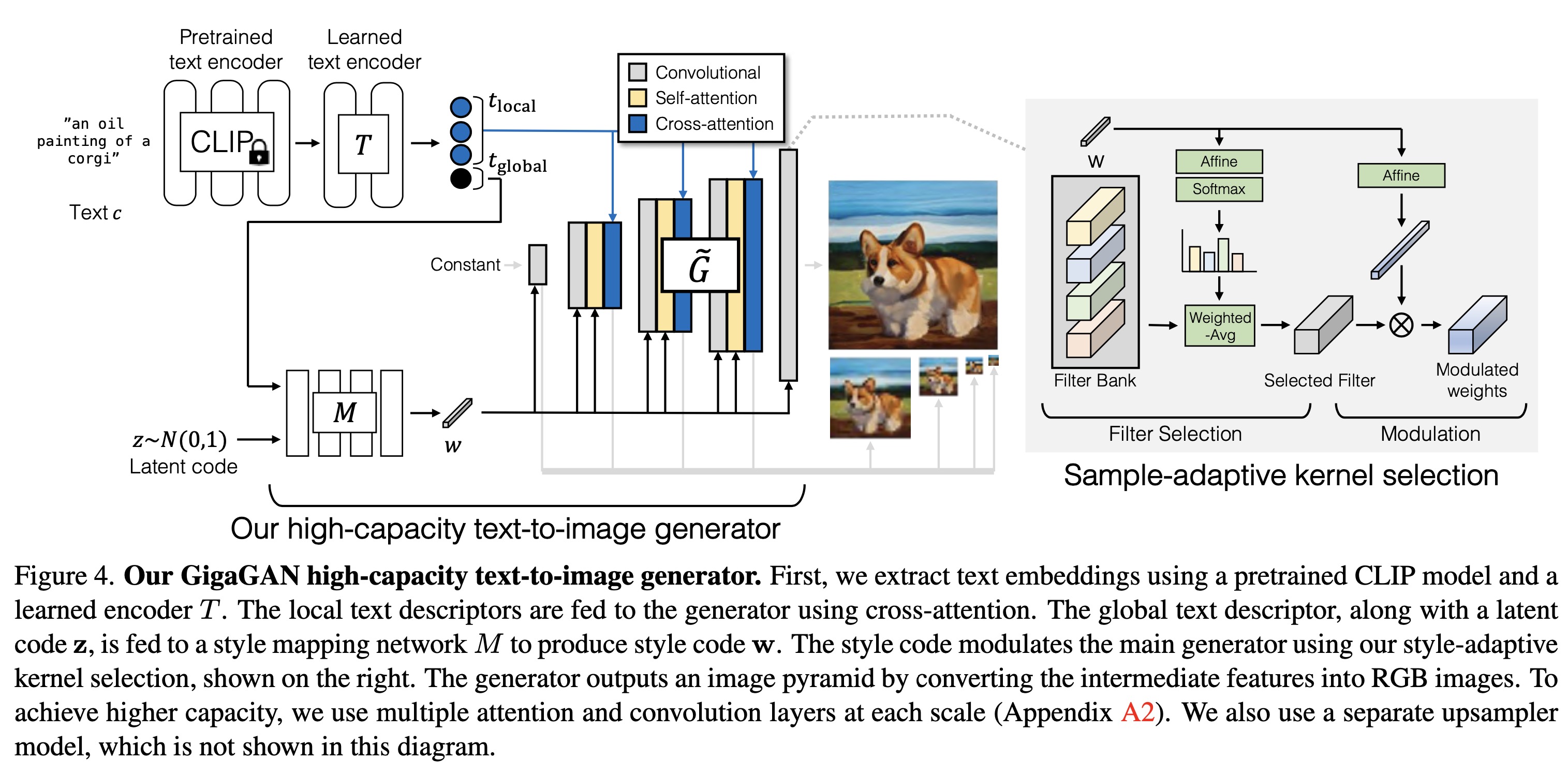
-
GigaGAN 的网络结构看起来是 StyleGAN 和 StableDiffusion 的结合体。
-
GigaGAN 的生成网络结构部分和 StyleGAN 类似。通过一个 Mapping Network 学习出一个 style code $w$。然后把 style code $w$ 送到 生成网络 G 中。StyleGAN的backbone是基于conv的,GigaGAN把 attention 层引入到了 StyleGAN的网络中。
-
GigaGAN是一个文生图模型。先通过 CLIP 的text encoder 和一个训练好的 text encoder 对文本进行编码,然后利用 Cross Attention 的方法把文本信息嵌入到生成网络G中。文本编码部分分成 $t_{local}$ 和 $t_{global}$。 global 比 local 多了一结尾符。local 用来作为 cross attention 的 query,golbal 和 z 作为 mapping 网络的input输入。
-
生成网络:$f_{l+1} = g^l_{xa}(g^l_{attn} (g^l_{adaconv} (f_l, w), w), t_{local})$。 网络生成是金字塔结构,分为五层(每层都会输出RGB,还记得 StyleGANv2的设计吗?)
$x_{i=0}^{L−1} = {x_0, x_1, …, x_4},$ with spatial resolutions ${S_i}_{i=0}^{L−1} ={64,32,16,8,4}$
-
判别器:(1)文本编码会被送到判别网络作为判别的一部分。(2)每一个尺度都会进行判别。
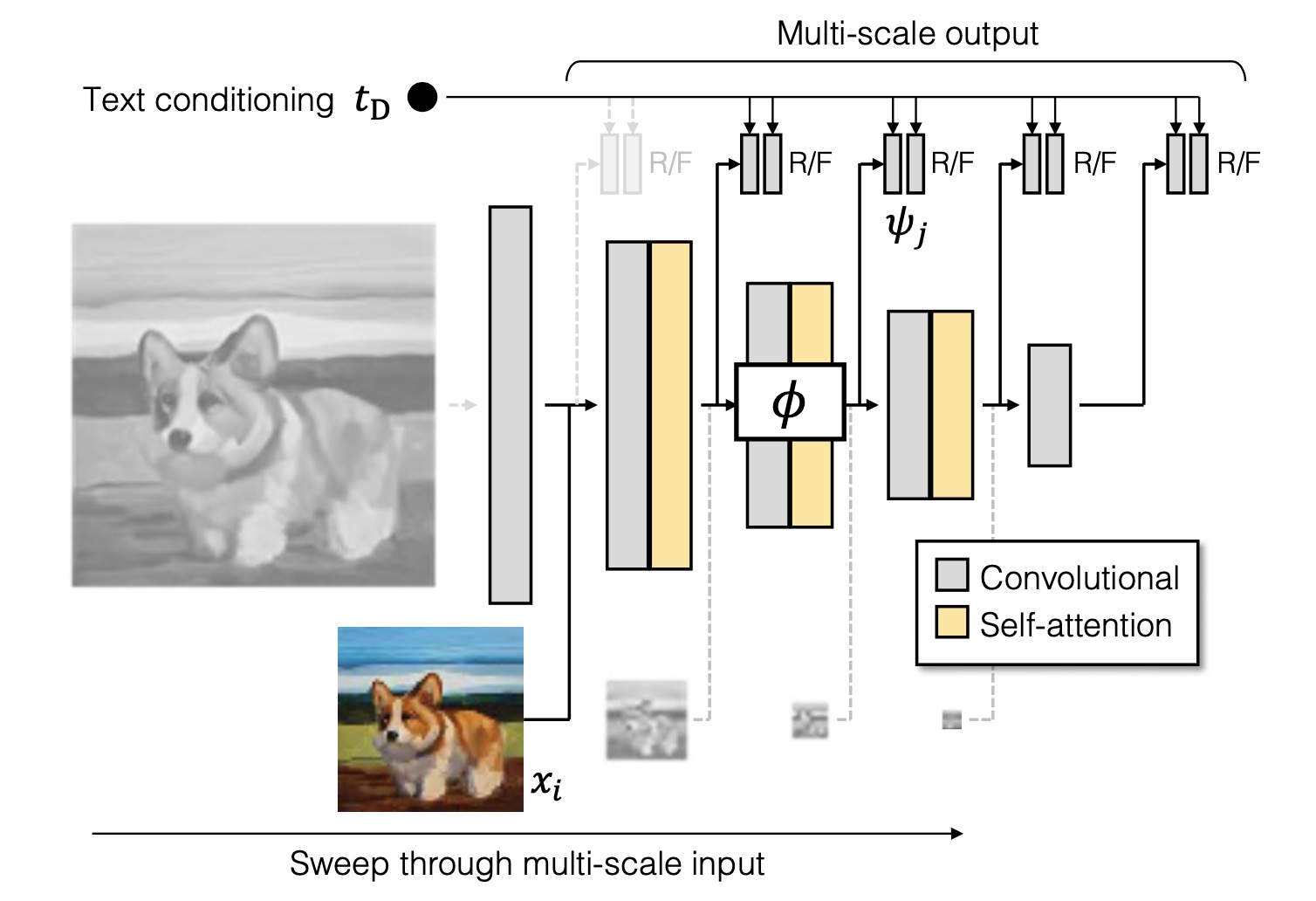
- 训练数据集是 LAIOA2B-en 以及 COYO-700M。
Experiments
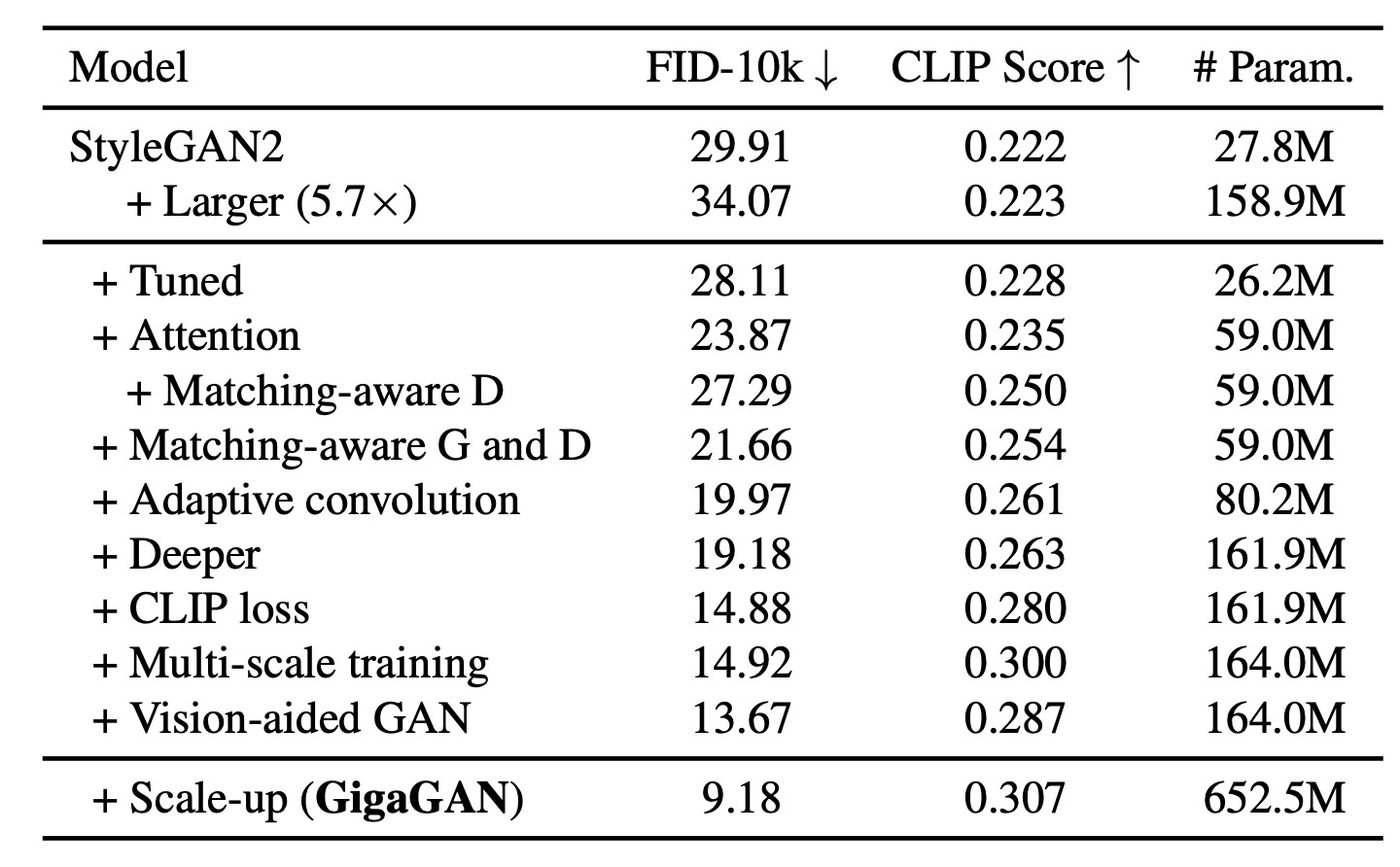
文中每一项优化的消融实验
和其他文生图模型的对比
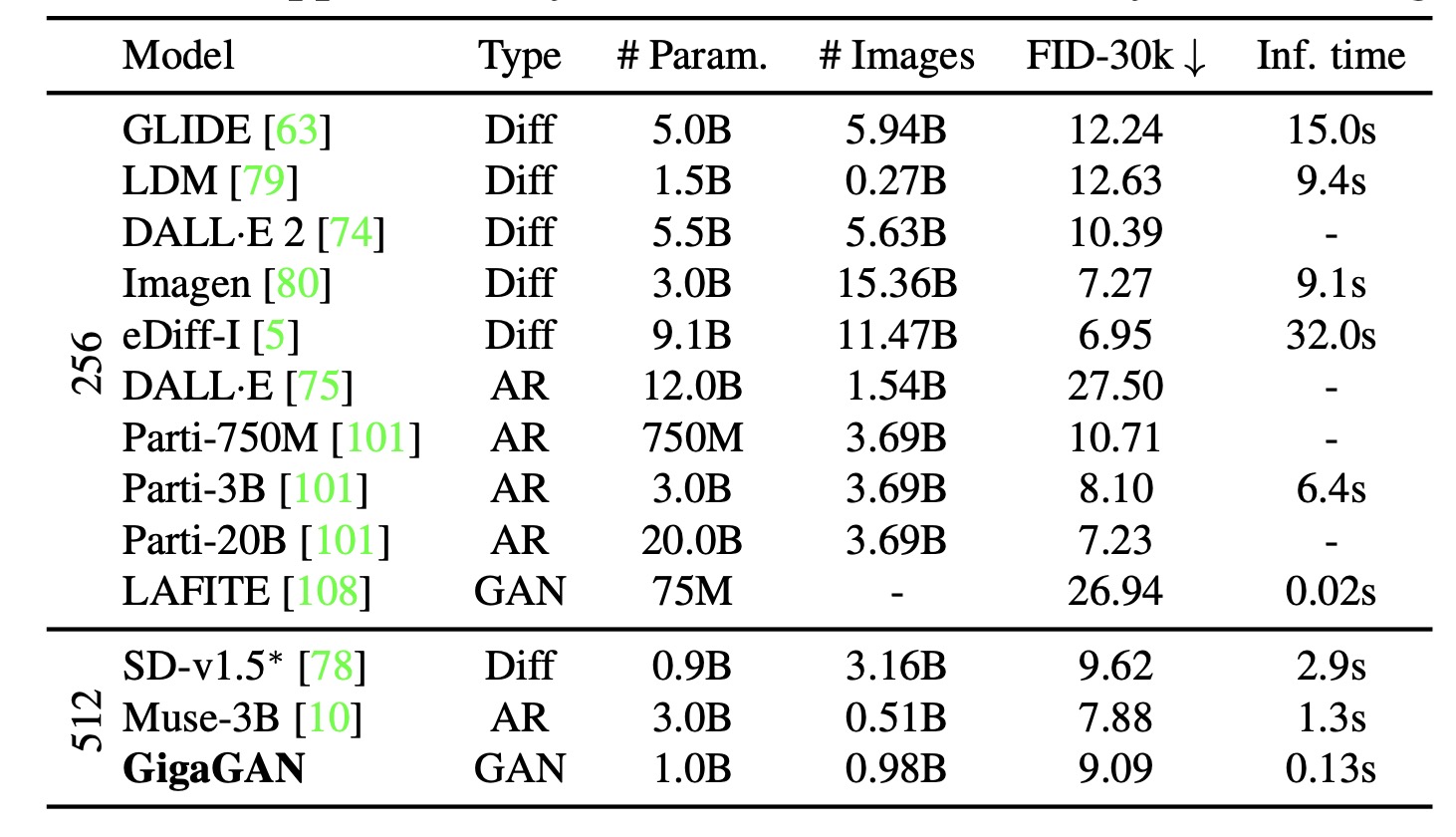
GigaGAN 比 DALLE·2,SD 和 Parti-750M 的 FID 更低。
and SD-v1.5 require 4,783 and 6,250 A100 GPU days, and Imagen and Parti need approximately 4,755 and 320 TPUv4 days for training。
GigaGAN sample的速度优势:
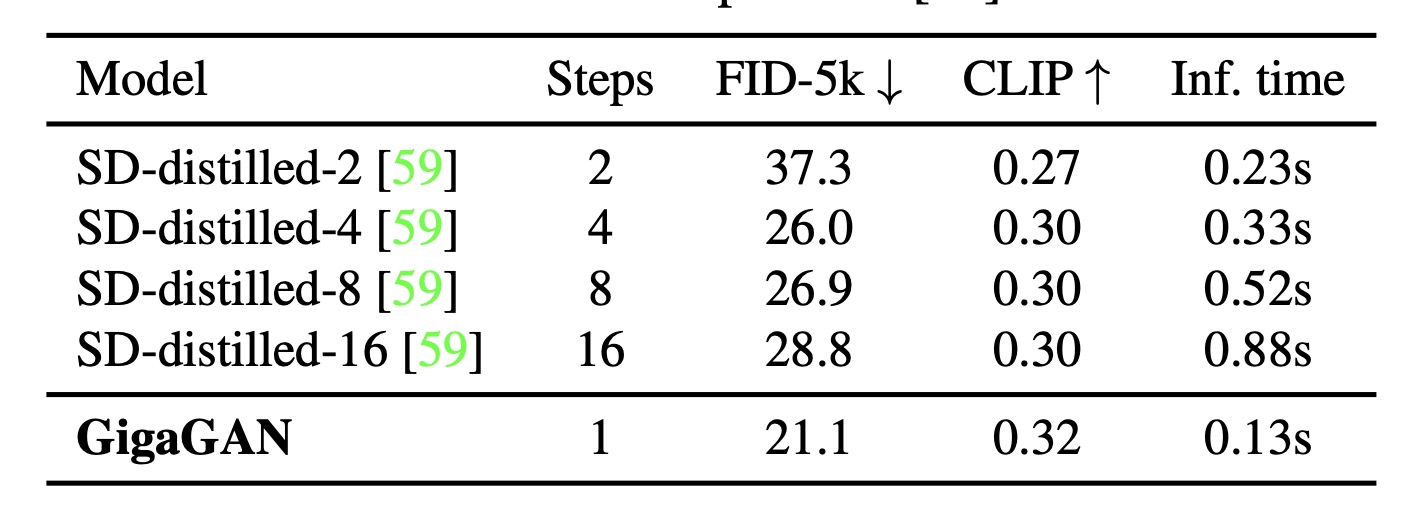
超分方面的量化指标:
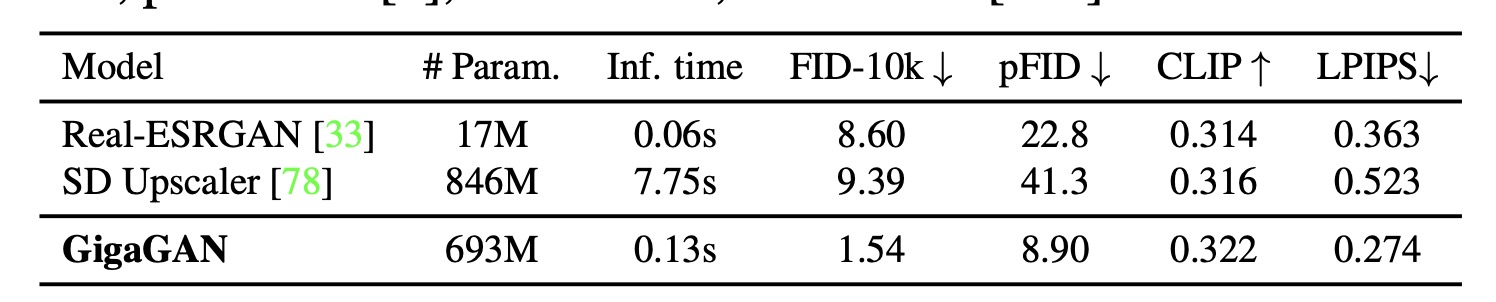
总结:
- 第一个把GAN做成文生图大模型的工作
- 从文中公开的结果来看,文生图效果从视觉角度来看,和Diffusion, AR 模型还是有一些差距。不排除是第一篇GAN文生图大模型,效果没办法一开始就做到非常好。
- 但超分的效果的确很好,而且速度也有着不小的优势。