review: HunyuanVideo: A Systematic Framework For Large Video Generation Model Training
https://github.com/Tencent/HunyuanVideo
腾讯开源的一个 13B 的视频生成模型 HunyuanVideo.
生成的视频帧率是 24fps,分辨率为720p。视频质量相较于目前其他的开源视频生成模型有着比较明显的提升。
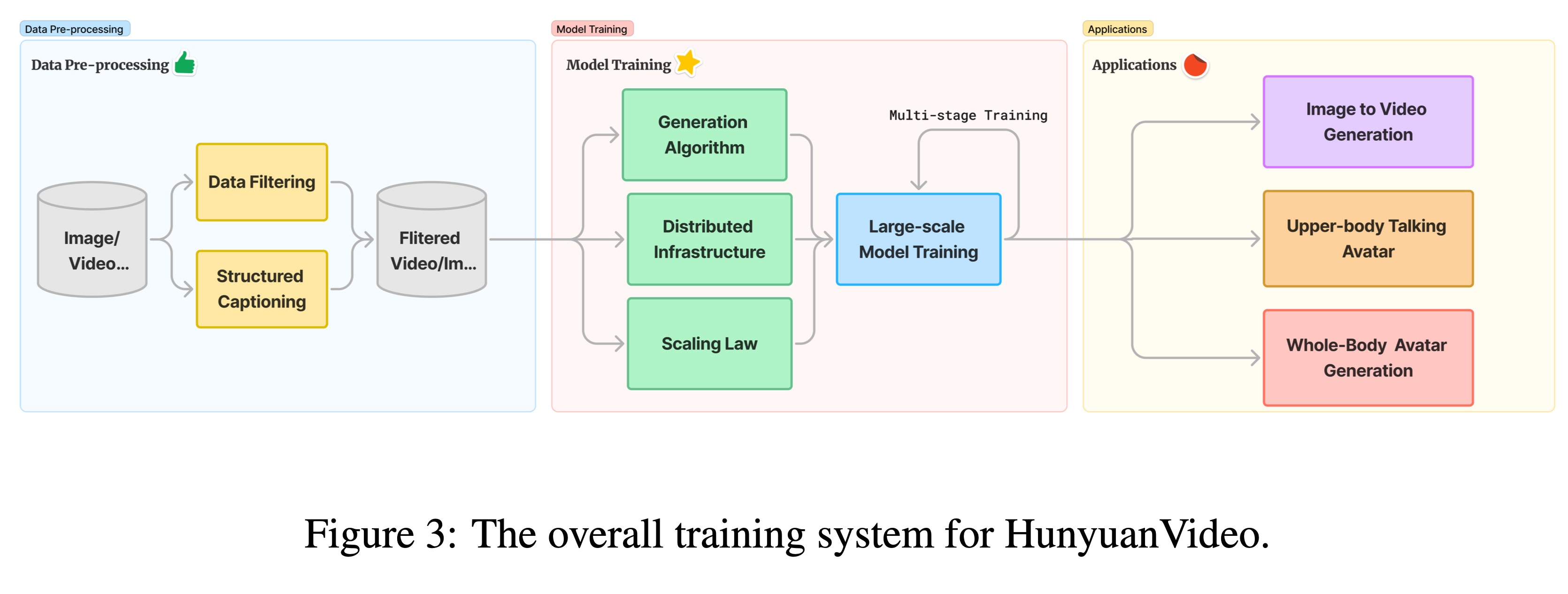
下图是混元的模型训练系统。主要分成三个部分,第一个部分是数据处理部分,主要是对网络爬取的数据进行清洗,以及caption label。第二个部分是模型训练,这里采用多阶段训练(分辨率维度的)。第三部分是算法部分,这里主要是一些比较偏上层的应用算法,有图生视频,上半生的talking head视频生成,以及全身形象视频生成。
关于数据筛选
- 利用 PySceneDetect 对视频进行分镜头切分。
- 然后利用 opencv 中的拉普拉斯方法筛选出单个视频中最清晰的那一帧,作为每个视频的起始帧。
- 使用内部的 VideoCLIP 来提取 视频片段的 embedding。这个 embedding 有两个作用。
- 利用 cosine 距离来进行视频去重。
- 利用 k-means 进行聚类,大概聚了 ~10k 的类别,用来进行重采样和数据平衡。
- 利用 Dover 对视频进行美观度评估。
- 训练了一个模型对视频进行清晰度和视觉模糊进行评价。
- 利用光流把静止和动作缓慢的视频筛除。
- 利用 OCR 模型把视频帧中存在过的字幕的视频筛除。
- 训练了一个类 yolo 的网络,把视频中的水印,边框,和 logo 去除掉。
下图是整体的数据处理流程:

在SFT阶段,我们构建了一个~1M的高质量数据集。这个数据集的数据从两个维度考察:
- 美学方面: 光照,色彩,空间布局,和物理规律。
- 运动方面:运动速度,动作完整性,以及是否有 运动模糊。
此外我们还构建了两个图像数据集:
- 第一个数据集包含 1B 级别的数据,主要用来做预训练。
- 第二个数据集在千万级别,用来做第二阶段的预训练。
数据标注:
我们训练一个 VLM 模型来给视频生成类结构化的caption。这个结构化的caption包括:
- 短描述:描述视频的主场景
- 密集描述:描述场景切换,以及相机移动等。
- 背景:视频主体所在的背景。
- 风格:比如纪录片,电影,真人等。
- 镜头类型:比如空中拍摄、特写镜头、中景拍摄或远景拍摄。
- 灯光:视频的灯光
- 氛围:视频中体现的氛围感,比如温馨,紧张,神秘。
模型结构:
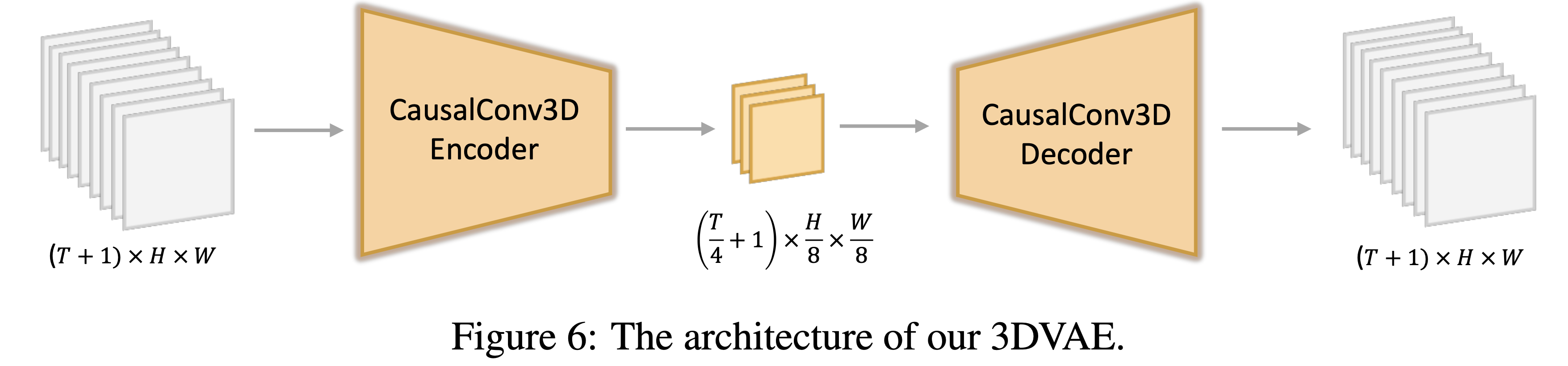
从文中介绍的模型结构来看,采用的是 3DVAE + DiT 结合的结构,和目前开源的 CogVideo 架构比较相似。其中3D VAE部分和 CogVideo 参数上也比较接近, T,H,W 维度 分别进行了 4x8x8 倍的压缩。
DiT 部分,是参考了的 12B 的 Flux 模型,改动是把 Flux 的 T5 换成了 MLLM 以支持多语种的输入。其余结构和 Flux 几乎一致。
3D VAE 的结构:
DiT 部分
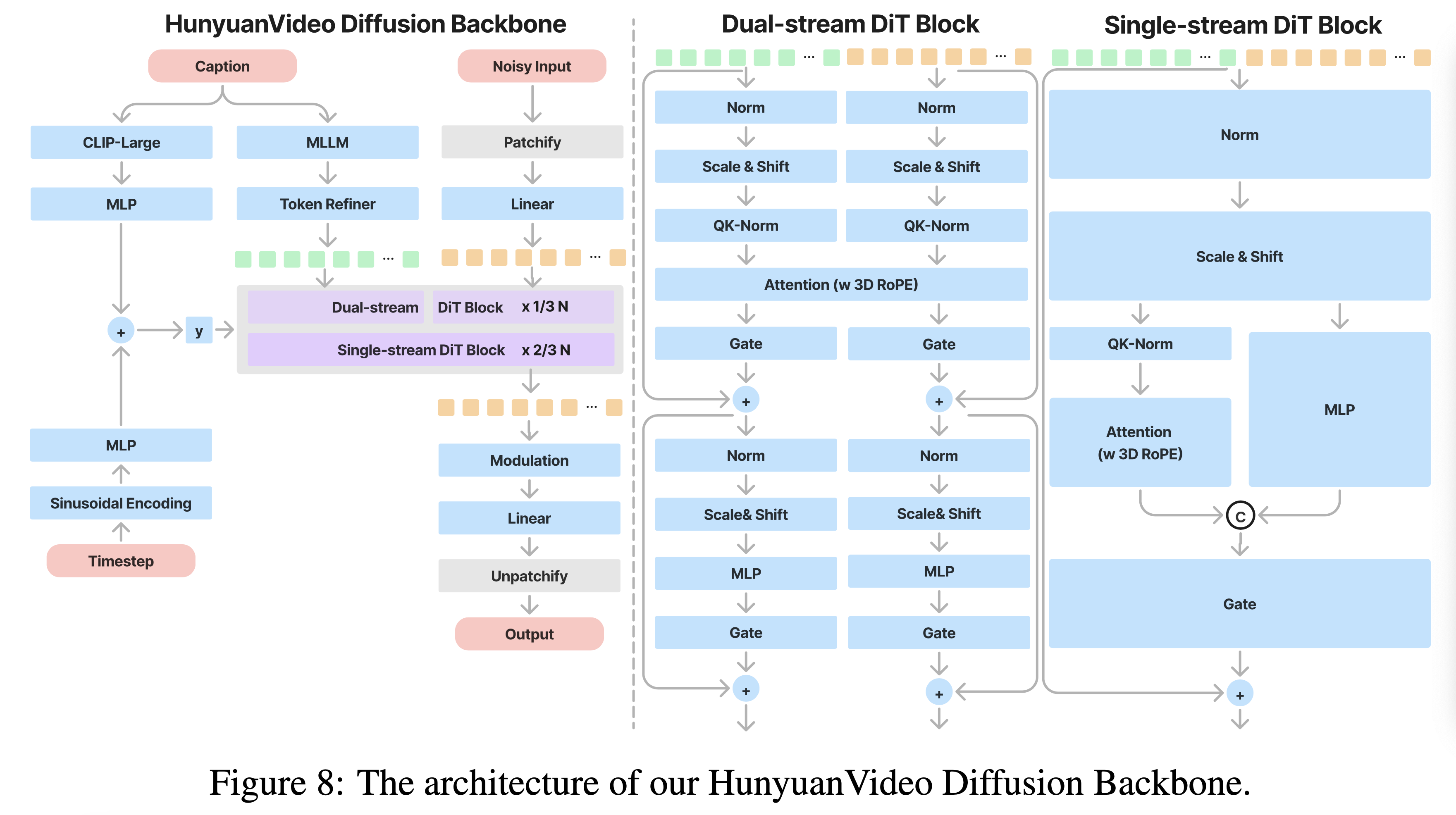
模型网络参数:

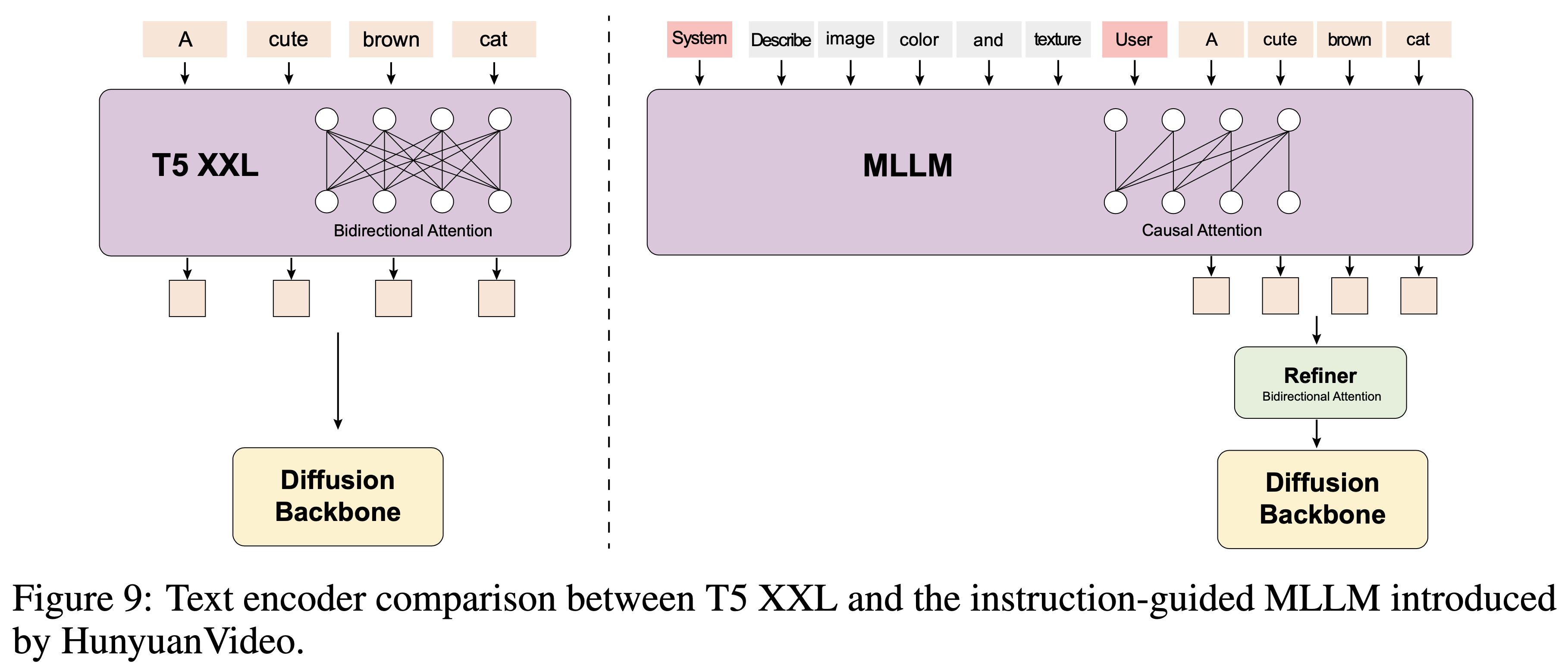
结构参考了 Flux ,文本部分用 MLLM 替换了 T5,这样可以支持中英文多语种输入。值得注意的是,文中提到T5 采用的是 双注意力机制,这对图片文本对齐效果有帮助,所以他们对 MLLM 进行改造引入了双注意力机制。
如下图:
训练的过程采用,文生图预训练,然后视频生成从低分辨率到高分辨率训练。
应用
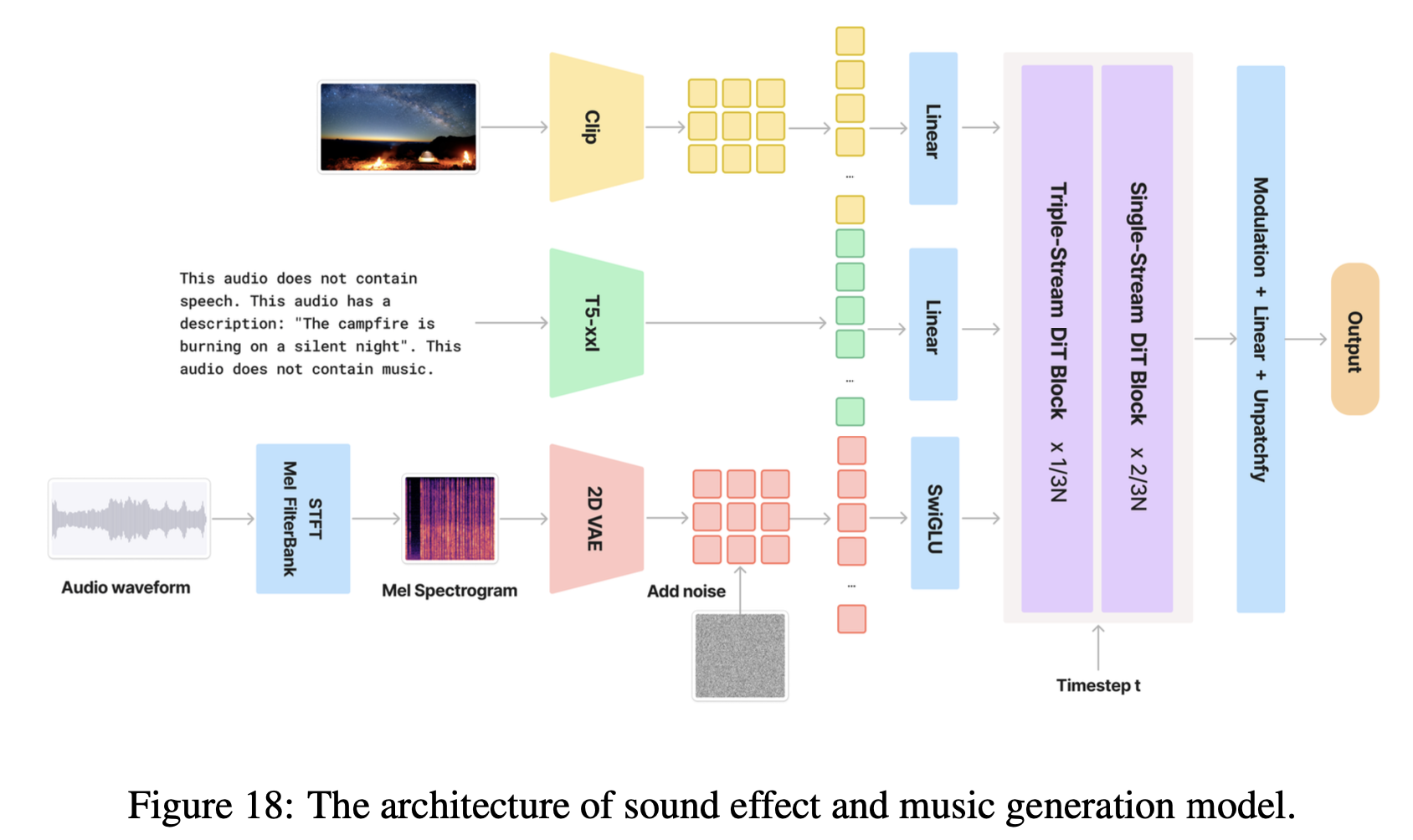
基于混元视频生成的DiT框架,还可以做类似音频生成的任务。框架如下图:
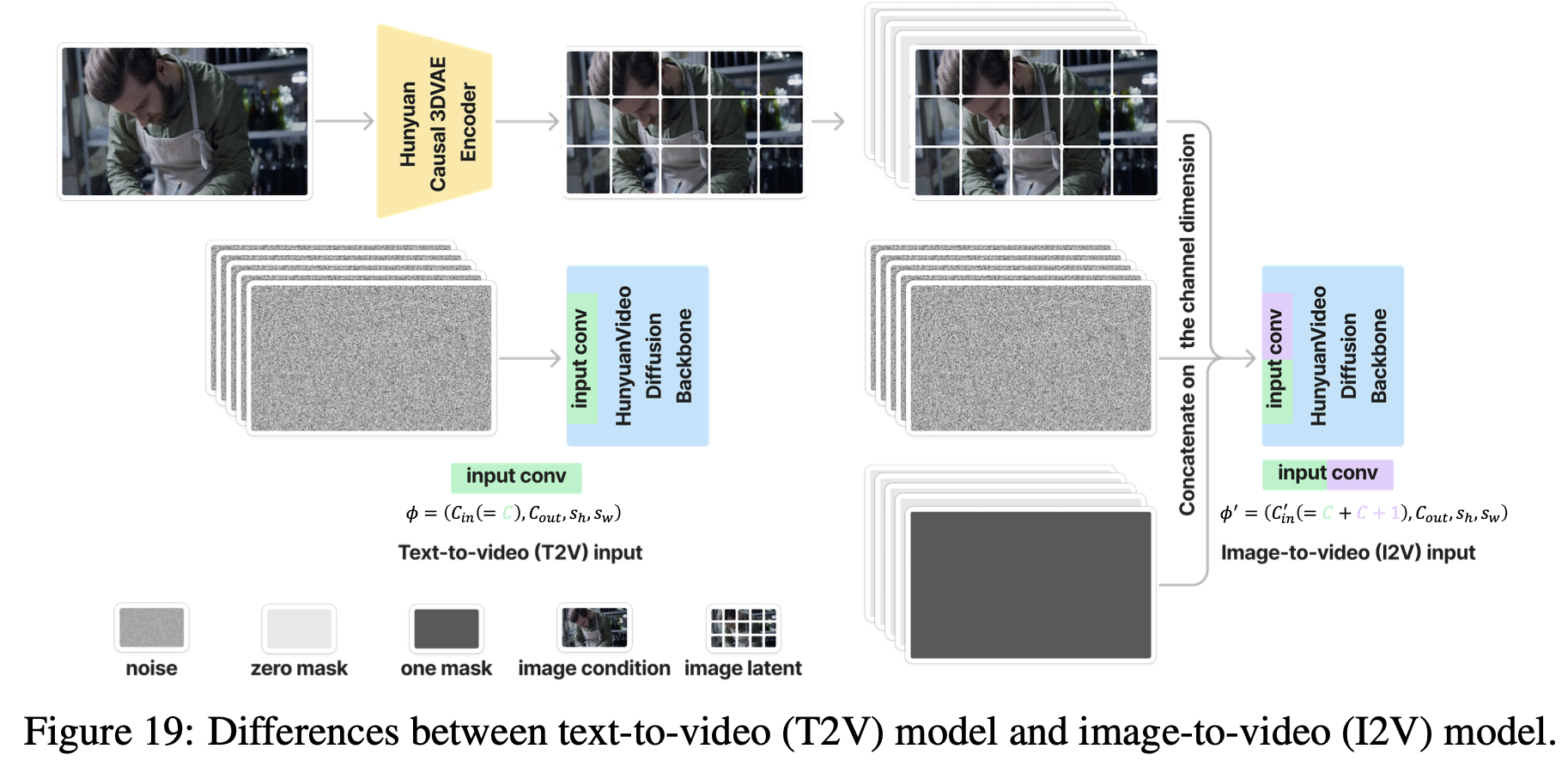
图生视频
还可以做根据音频/姿态表情驱动图片生成视频:
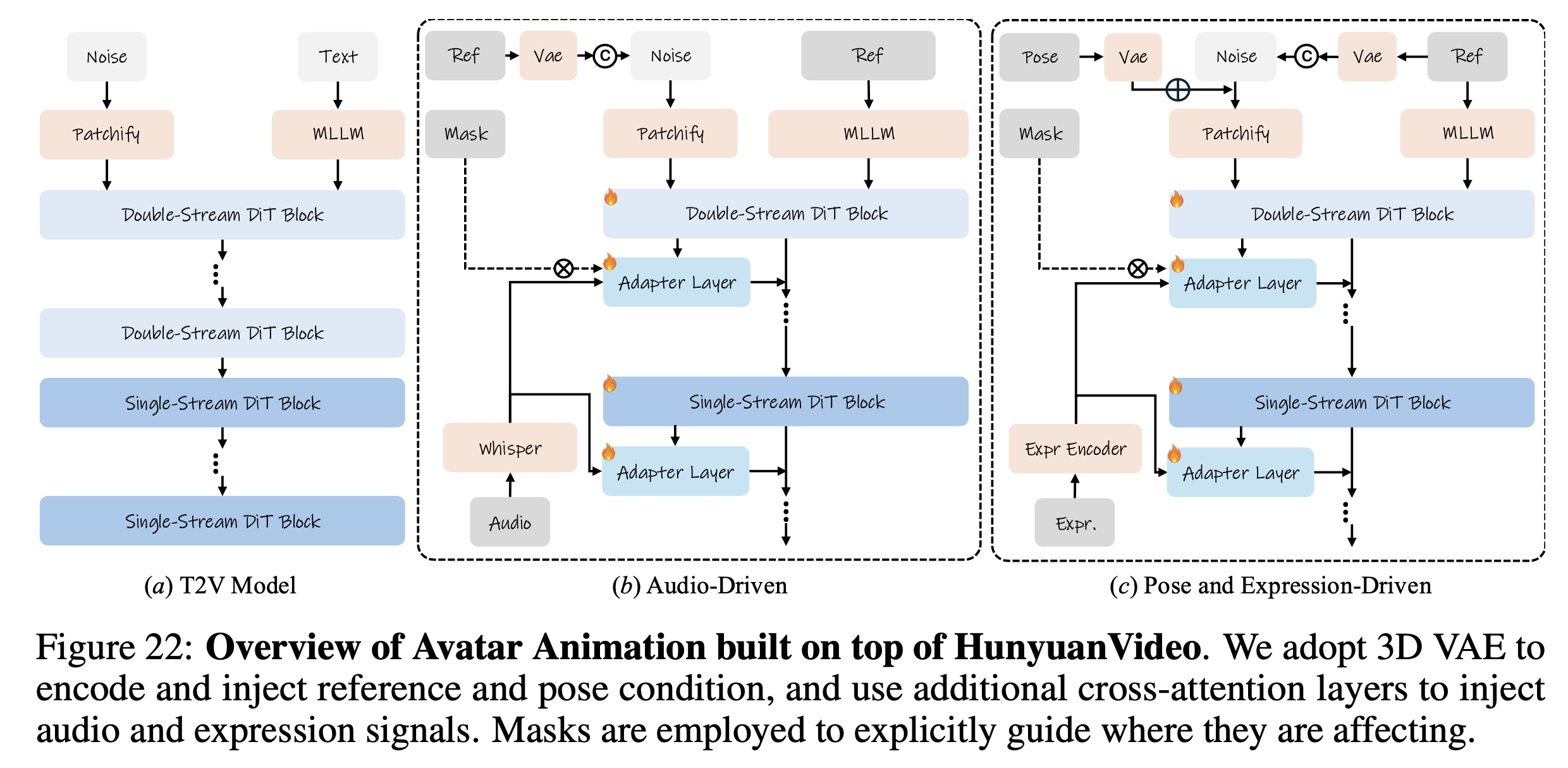
不过他的 ref 是过MLLM 的,这个有点怪, MLLM 是语言模型,不知道为啥可以吃 ref 作为输入。
音频和姿态的输入方式,和之前的工作比较接近。表情部分,文中用的是 VASA 的表情提取器,不过VASA也没有开源,估计是自己训练了一个。
总的来说,混元开源的视频生成模型,生成效果是目前开源中最好的模型。