Review Imagen
本文是对论文 Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding 的简介
Imagen 是 Google 在22年5月发表的一篇关于文生图任务的论文。其主体框架基于 Diffusion 模型。和其他文生图(比如 DALLE-2,Stable Diffusion)模型不同的地方是:
- Imagen 使用大语言模型(T5-XXL 模型)。论文中使用大语言模型作为condition,在文生图任务上表现很好。
- Imagen 基于像素空间生成图像。DALLE-2, Latent Diffusion 是基于 Latent 空间生成图像。
Imagen 的效果如下:
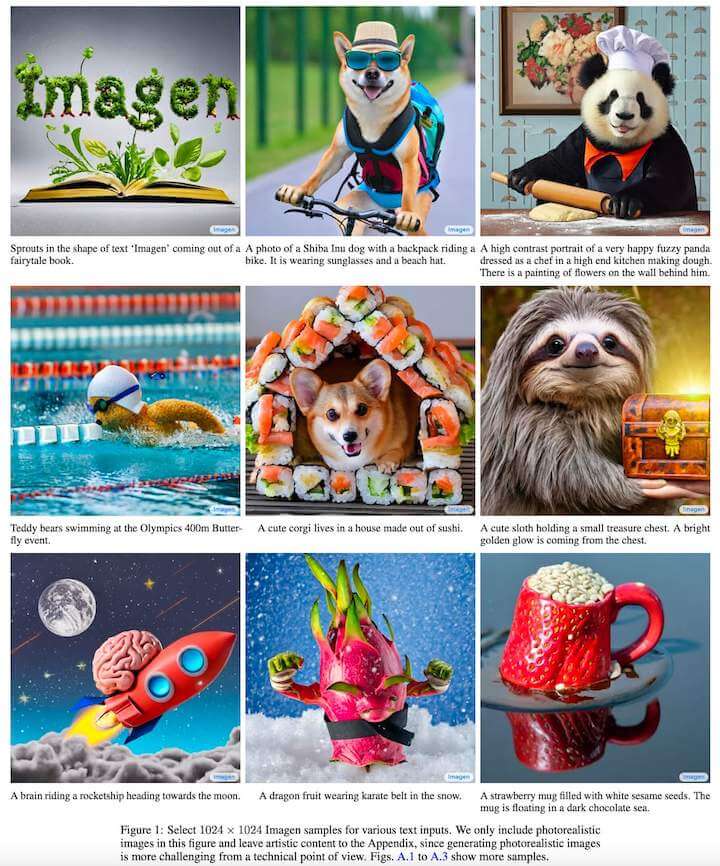
Imagen的核心贡献:
- 利用预训练大语言模型提取文本的 embedding 作为 condition 对文生图任务非常有效。并且实验表明增加语言模型的大小比增加 diffusion 模型大小要更加有效。
- 动态阈值,改进 diffusion 采样过程。动态阈值使得在生成时可以利用比较的大的引导权重,使得生成的图片更加真实和逼真。
- Diffusion 模型框架采用 Efficient U-Net
Large guidance weight samples:
增大 classifier-free guidance 的权重可以改善生成图像-文本对齐,但是会破坏图像的保真度,产生高饱和度,和不自然的现象。实验发现这是由于高 cfg 权重会导致训练-测试不匹配。在采样步骤 $t$ 时,被预测的 $\hat{x_0}^{t}$ 必须在训练数据 x 的相同范围内,即[-1, 1]之间,但我们发现高 cfg 权重,会导致预测的 x 超出这个范围。扩散模型在采样过程中会连续应用其自身的输出,当中某一步出现这类训练-测试不匹配的情况,会导致生成的图像不自然。
为了解决这个问题,Imagen 提出静态阈值和动态阈值。
静态阈值法:在 diffusion 模型预测 x0 的过程中,将元素逐个剪切到 [-1, 1] 范围内。前向推理过程中,在使用比较大的cfg时,利用静态阈值法是必不可少的,它可有效防止生成空白图像。但当 cfg 很大时,静态阈值法仍会导致图像过度饱和和细节不足。
动态阈值法:在每个采样步骤中,我们将 $s$ 设置为 $\hat{x_0}^{t}$ 中某个百分位的绝对像素值,如果 s>1,则将 $\hat{x_0}^{t}$ 阈值化到范围[−s,s],然后除以 s。动态阈值将饱和像素(靠近-1和1的像素)向内推,从而在每个步骤中防止像素饱和。动态阈值可以显著提高照片逼真度和图像文本对齐度,特别是在使用非常大的引导权重时。
Robust cascaded diffusion models : 级联扩散模型
Imagen 的模型结构如下:
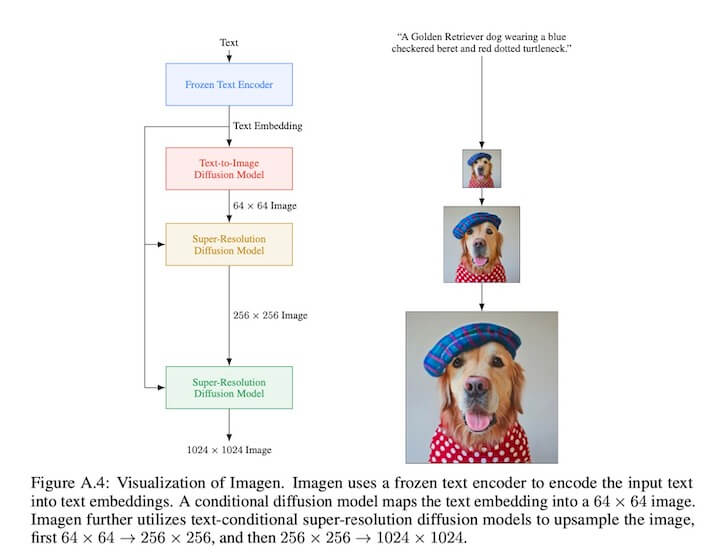
Imagen 采用多分辨率级联扩散模型来完成高分辨率的图像生成工作。具体来说,网络分成三个部分,是一个 64x64 的基础模型,以及256x256, 1024x1024 两个超分模型;
Imagen论文实验发现,级联扩散模型在生成高保真度的图像方面非常有效。
网络结构上:
三种不同分辨率的 diffusion 模型均采用的是 UNet 结构。网络通过一个池化的文本 embedding 与 diffusion timestep embedding 相加,通过 cross-attention 的方式把文本信息注入到 diffusion 网络中。(这里64x64, 256x256, 1024x1024 三个网络都会做 cross-attention 的操作)
文中发现在attention和pooling层中对 text embedding 采用 layer normalization 可以显著提高性能。
另外为了加速,imagen 在 256x256, 1024x1024 两个模型中,把 self-attention 层去掉。
文生图模型测评:
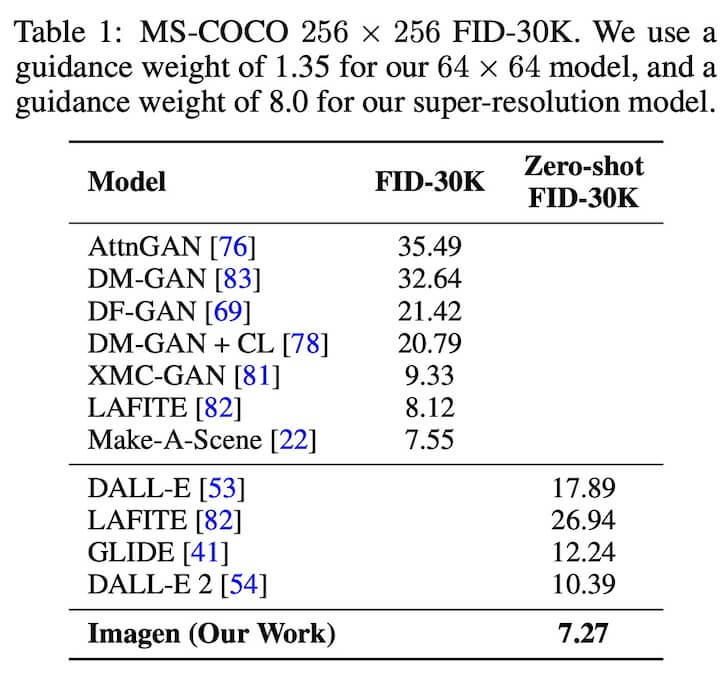
- 文生图测评一般是从 CLIP score 和 FID score 两个维度来定量测试。Imagen 在 COCO 测试集上两个维度均达到 SOTA 的效果。
- 生成类任务一般还需要做一些定性的测试,利用类似 user-study 的方式测评生成结果整体质量。Imagen 设计了两种问题,让测试员去回答:
- “哪张图片更加真实” - 测量图像生成质量。
- “哪张图片更符合语义” - 测量图像文本一致性。
DrawBench
不过用 COCO 数据集来测评文生图有一定的局限性,它无法很好的评价出不同模型的差异。所以 Imagen 提出了一个新的文本测评集合,叫 DrawBench.
DrawBench 包含11类 prompts,来测试模型的不同能力。例如颜色,数量,空间关系,场景中的文本,以及对象之间的异常交互。
Experiments
模型大小
| 64x64 | 256x256 | 1024x1024 |
|---|---|---|
| 2B | 600M | 400M |
模型训练:三个模型迭代步数是一致的:batch size 2048,训练 2.5M steps 。
COCO 上的测评结果:
DrawBench 上的测评结果:
Imagen 结果和 DALL-E, DALL-E 2, Latent Diffusion, VQ-GAN对比,均有优势。
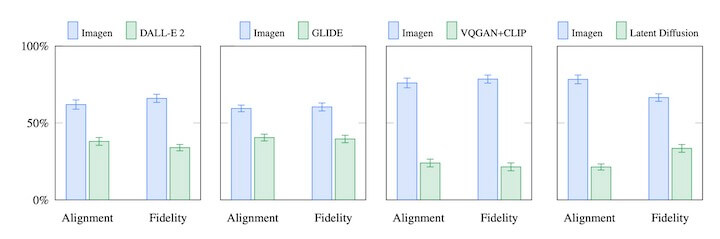
对 Imagen 的分析:
- 增加 text encoder 模型大小是非常有效的。
- 增加 text encoder 模型大小比增加 diffusion 模型大小有用。
- cfg 动态阈值非常重要。
- 在 DrawBench 测评集上,对比 T5-XXL 和 CLIP 的生成图片结果,人们选择 T5-XXL.
- 噪声增强非常重要。
- 文本潜入方法很重要。(cross-attention 的方法,效果是最好的)
- Efficient U-Net 很重要。 内存更少,收敛速度更快,这在大模型训练中非常重要。
开源
deepfloyd 基于 Imagen 这篇 paper 实现了 IF ,并进行了开源。其网络结构如下:
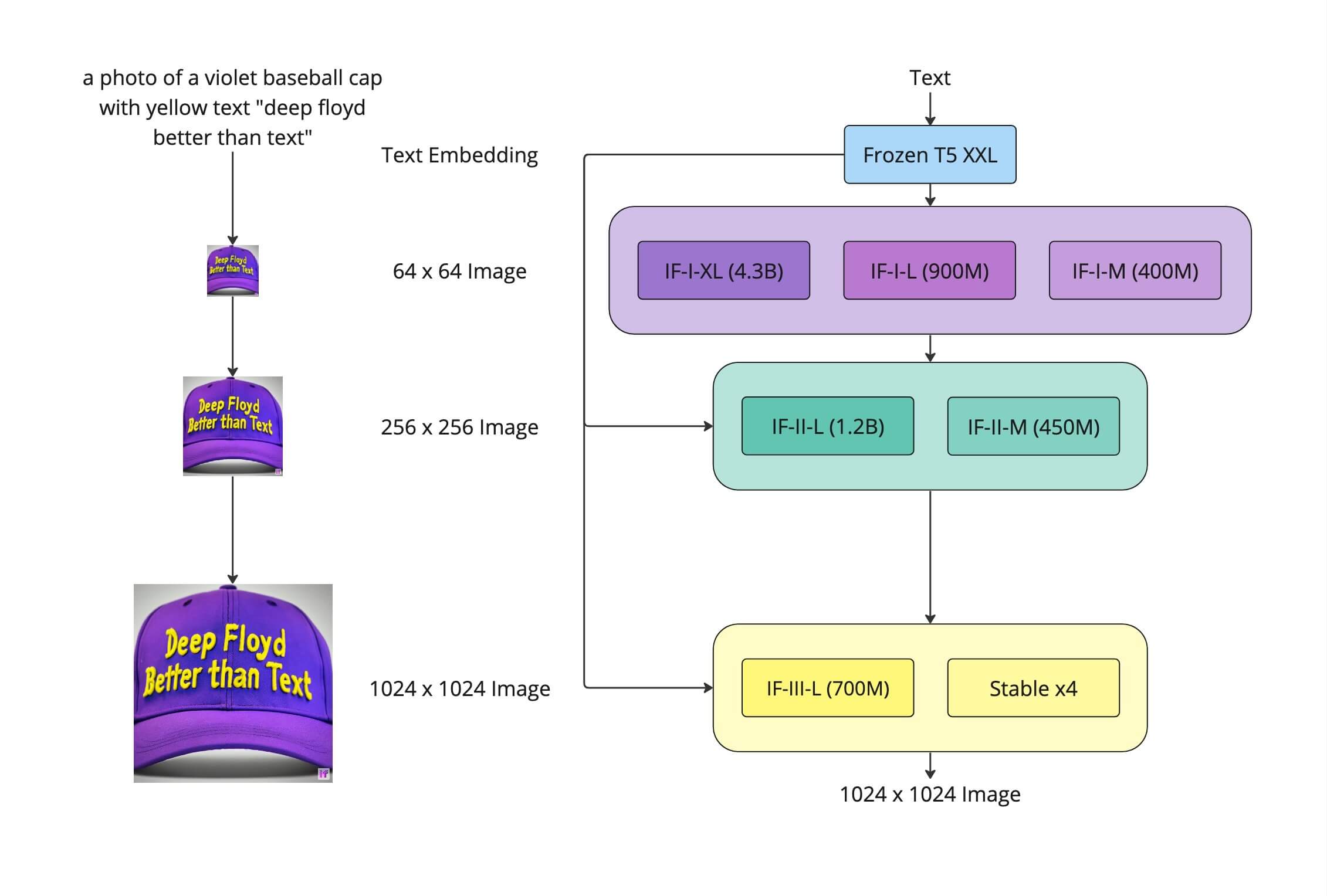
该结构基本遵循 Imagen 论文中的方法,不同的地方是 64x64 的模型采用了 4B 模型。
测试下来,DeepForld 相较于基于 CLIP 做文本 condition 的模型在:
- 颜色
- 数量
- 空间位置关系
这几项上有着一定的优势。
总结
- Imagen 利用 Diffusion 模型,结合大语言模型在文生图上取得了 SOTA 的效果,从定量和定性两个方面都击败了DALLE-2等一众模型。
- 提出 DrawBench 测试集,凸显了语言模型的优势。
- 开源的 DeepForld 实际测试效果确实不错。
以上就是对 Imagen 模型的简介。