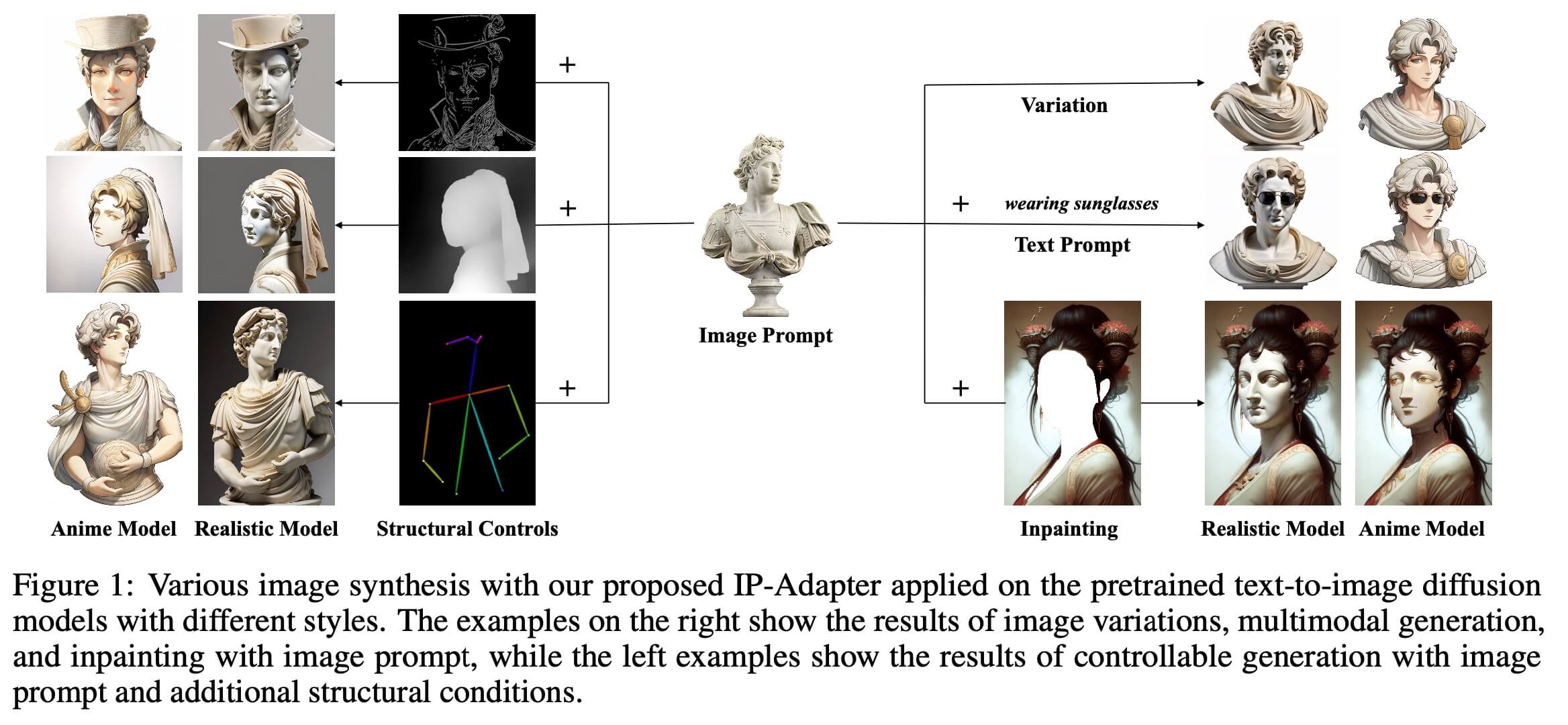
本文提出一种 Image Prompt Adapter 方案,实现了类似 Image Prompt的方案。从上图,我们可以看到通过IP-Adapter,我们可以实现(1)Image Variation的能力,如图片中的右上角,image variation 简单来讲就是对目标图片做一些变换的同时,还保留该Image的主要特征。(通俗的来讲是让人看得出来是同一个主体)(2)编辑和inpainting,当我们不好用文本来描述,需要生成的图的内容,或者inpaint区域的内容时,可以用 IP-Adapter 以 Image prompts的方式来完成。(3)IP-Adapter 也可以和 Controlnet兼容,通过Controlnet+IPAdapter,我们可以生成目标主体+动作的图片。
所谓Image Prompt,可以类比Text Prompt。比如 https://huggingface.co/lambdalabs/sd-image-variations-diffusers 这个image variation的工作,就是在SD模型基础上,把 condition 部分的text embedding 换成 image embedding,然后重新训练一个模型。 这个重新训练的方法效果也是不错的,不过他有两个问题,(1)需要重新训练模型,而社区里面一些其他上下游的工作,比如Controlnet等,就无法和这个模型一并使用了(2)image variation模型condtion部分只能接受 image prompt,text prompt被移除了。这也导致他使用场景会受限。
IP-Adapter 是一个在SD模型基础上,保留原始SD模型结构和权重的基础上,增加了一个 Image Prompt 分支。具体来说,这个分支分为两个部分, Image Encoder 和 Decoupled Cross-Attention。
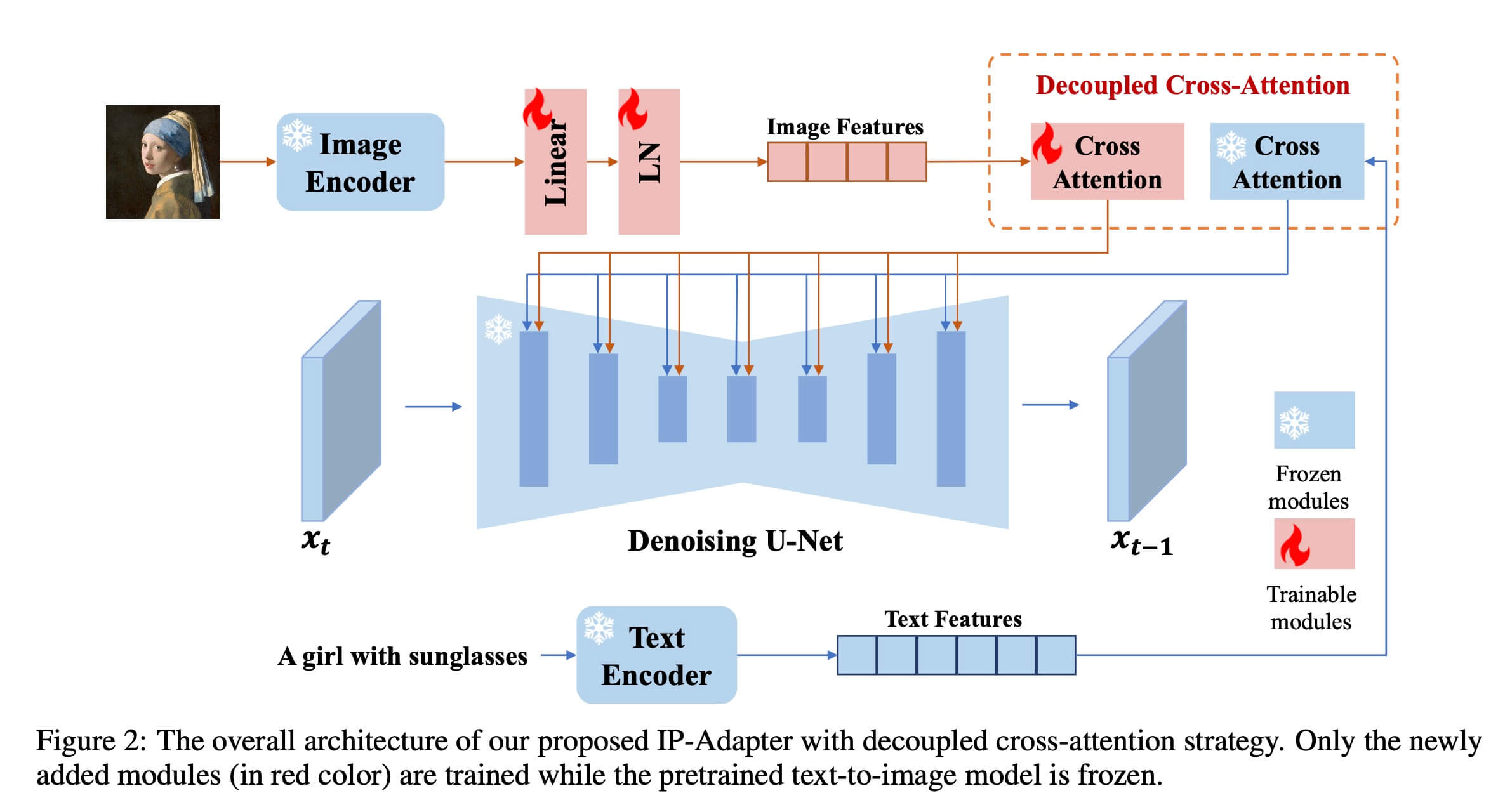
Image Encoder
这部分比较简单,首先会 image 进行 CLIP 提取 embedding 操作,这里提取的是CLIP的倒数第一层,然后设计了一个 linear + 一个 Layer normalization 两个可训练的部分,经过这两个部分得到 Image embedding. 此时 这个 Image embedding 类似 SD原始模型中Text经过CLIP提取的text embedding。
Decoupled Cross-Attention
这部分结构其实也是比较清晰的,主要是对SD模型中的Cross-Attention部分的 K, V 切换成 Image 的 embedding。
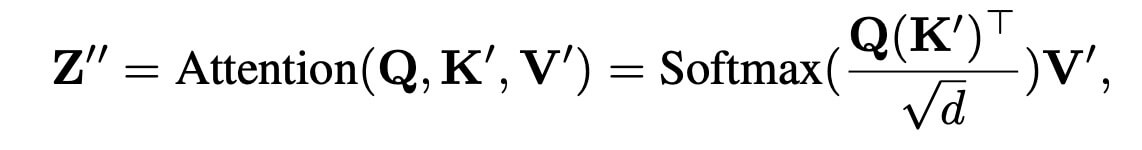
where, $Q = ZW_q$, $K^′ = c_iW_k^′$ and $V^′ = c_iW_v^′$ are the query, key, and values matrices from the image features. $W_k^′$ and $W_v^′$ are the corresponding weight matrices.
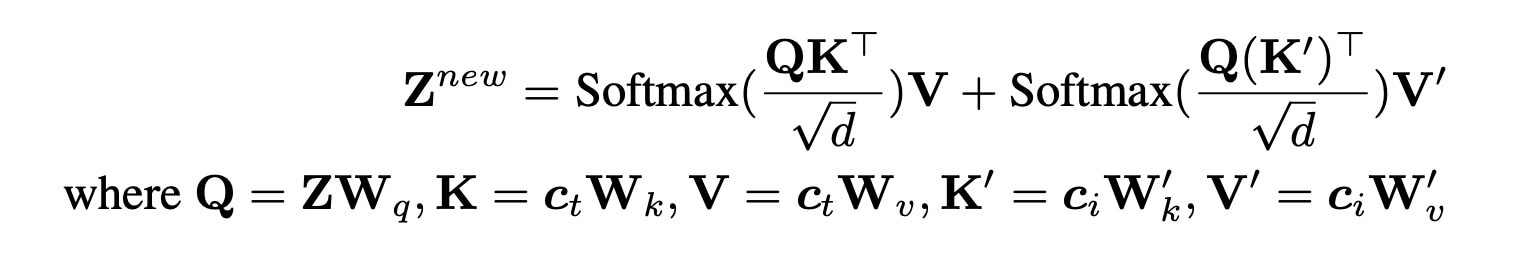
训练过程中,把原始UNet锁住,只是训练 $W_k^′$ and $W_v^′$。
以下是摘取的关于 decoupled cross-attention 部分的code:
key = attn.to_k(encoder_hidden_states)
value = attn.to_v(encoder_hidden_states)
query = attn.head_to_batch_dim(query)
key = attn.head_to_batch_dim(key)
value = attn.head_to_batch_dim(value)
attention_probs = attn.get_attention_scores(query, key, attention_mask)
hidden_states = torch.bmm(attention_probs, value)
hidden_states = attn.batch_to_head_dim(hidden_states)
# for ip-adapter
ip_key = self.to_k_ip(ip_hidden_states)
ip_value = self.to_v_ip(ip_hidden_states)
ip_key = attn.head_to_batch_dim(ip_key)
ip_value = attn.head_to_batch_dim(ip_value)
ip_attention_probs = attn.get_attention_scores(query, ip_key, None)
ip_hidden_states = torch.bmm(ip_attention_probs, ip_value)
ip_hidden_states = attn.batch_to_head_dim(ip_hidden_states)
hidden_states = hidden_states + self.scale * ip_hidden_states
IP-Adapter 还有一个 fine-grained 版本,你主要修改的地方是 image encoder部分,fine-grained 版本, 首先对Image提取CLIP倒数第二层的feature,然后搭建一个transformer网络,利用transformer网络学习得到 image embedding, 然后把这个 image embedding 作为 decoupled cross-attention 的输入。

从上图可以看出 fine-grained 模型对原图一些细节部分保持的更好一些。
小结: IP-adapter 在 SD 原模型基础上加入 image prompt,通过adapter的方式让SD模型在保留原有能力的基础上,增加了image prompt的能力。从结果上来看,其对image 的variation,edit 的能力都是非常不错的。