src: “FLUX.1 Kontext: Flow Matching for In–Context Image Generation and Editing in Latent Space” (arXiv:2506.15742v2)
摘要
Black Forest Labs 提出一个新的生成模型:FLUX.1 Kontext。FLUX.1 Kontext 是一个面向图像生成和编辑的算法模型。
它的优点有:
- 多功能统一:单个模型可以处理多种复杂的编辑和生成任务。
- 一致性:在连续编辑中能够高度保持角色和物体的身份特征,适合故事板创作、品牌形象设计等需要连续性的应用。
- 交互式速度:通过蒸馏对抗的方法减少了推理时需要的步数,生成速度快。
- 广泛的应用场景:论文展示了其在产品摄影,人物表情编辑,风格迁移和基于视觉提示(如红框)的局部编辑等多种场景下的强大能力。
下面这张图展示 Kontext 的能力,从(a)去除遮挡,得到(b),把(b)改成在Freiburg的街头自拍,得到(c);最后把(c)改成下雪得到(d)。
整个多轮编辑效果质量都非常高。

技术与原理
模型的核心思想是把所有输入(文本指令, 上下文图像,目标图像)都转换成统一的 token 序列进行处理。
序列拼接(Sequence Concatenation) 是实现统一架构的关键。
- 上下文图像和目标图像均使用 VAE encoder 得到 latent 之后,patchy 成 Token 序列。上下文图像的Token序列附加在目标图像的Token序列之后,形成一个更长的序列。这个组合序列被一同送入模型的视觉处理流中。该方法被证实比通道维度的拼接更为有效。
如下图所示:
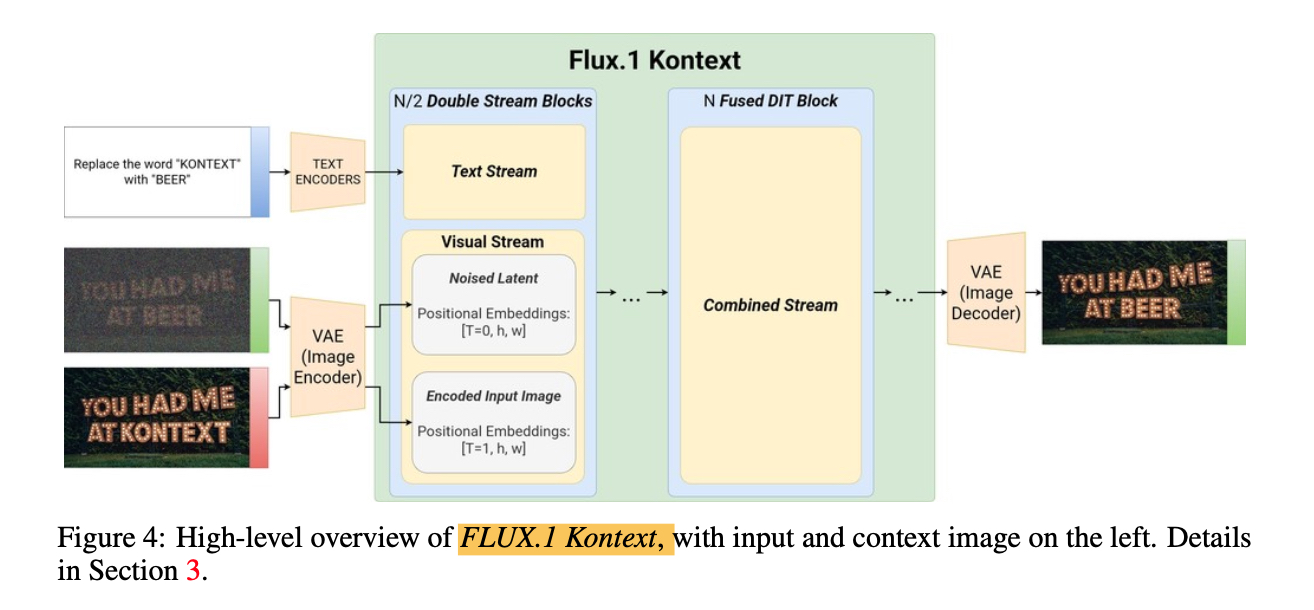
位置编码方案
为了让模型准确区分拼接后序列中的上下文图像部分和目标图像部分,Kontext 采用了一种新的位置编码方案。
- 3D 旋转位置潜入(3D RoPE):模型使用 3D RoPE 来编码每个 Token 的时空位置信息(t, h, w)。
- 虚拟时间步(Virtual Time Step):这是区分上下文图像和目标图像的核心技巧。目标图像的Token的 t=0, 而上下文图像Token的 timestep 设置成 t=1。这个虚拟时间步,在逻辑上清晰地将两者分离开来,使得模型在处理时能够明确各自的角色。
流匹配
Kontext 是基于 Rectified Flow Matching 构建的模型,在 latent 空间上通过学习 “如何从噪声到真实图像” 来生成图片或编辑图片。
Kontext 模型学习条件分布:p_θ(x|y,c)
- x: 目标图像(模型要生成的)
- y: 上下文图像(可以为空)
- c: 文本指令
当 y != ∅ 时,图像局部编辑 当 y = ∅ 时,文生图
训练数据
Kontext 在训练的过程中使用到了百万级别的 (x|y,c) 数据paired对,这个数据集是 Kontext 效果如何之好的核心因素。
Loss 函数
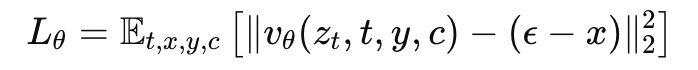
KontextBench
为了更加系统准确的评估模型性能,研究团队构建了KontextBench。
- 构成: 108 张基础图像,通过 prompts 组合成 1026个独特的 “图像-提示” 对。
- 任务分类: KontextBench 覆盖了五个核心任务类别:
- 局部指令编辑
- 全局指令编辑
- 角色参考
- 风格参考
- 文本编辑
下面是一些show case:

附录 - 代码:
位置编码:
# 下面是 target image 和 incontext image 位置编码代码,img_ids t set 0,img_cond_ids set 1
img_ids = torch.zeros(h // 2, w // 2, 3)
img_ids[..., 1] = img_ids[..., 1] + torch.arange(h // 2)[:, None]
img_ids[..., 2] = img_ids[..., 2] + torch.arange(w // 2)[None, :]
img_ids = repeat(img_ids, "h w c -> b (h w) c", b=bs)
img_cond_ids = torch.zeros(height // 2, width // 2, 3)
img_cond_ids[..., 0] = 1
img_cond_ids[..., 1] = img_cond_ids[..., 1] + torch.arange(height // 2)[:, None]
img_cond_ids[..., 2] = img_cond_ids[..., 2] + torch.arange(width // 2)[None, :]
img_cond_ids = repeat(img_cond_ids, "h w c -> b (h w) c", b=bs)
推理代码
img_cond_seq : in context image sequence
img_cond_seq_ids : in context image sequence position embedding
def denoise(
model: Flux,
# model input
img: Tensor,
img_ids: Tensor,
txt: Tensor,
txt_ids: Tensor,
vec: Tensor,
# sampling parameters
timesteps: list[float],
guidance: float = 4.0,
# extra img tokens (channel-wise)
img_cond: Tensor | None = None,
# extra img tokens (sequence-wise)
img_cond_seq: Tensor | None = None,
img_cond_seq_ids: Tensor | None = None,
):
# this is ignored for schnell
guidance_vec = torch.full((img.shape[0],), guidance, device=img.device, dtype=img.dtype)
for t_curr, t_prev in zip(timesteps[:-1], timesteps[1:]):
t_vec = torch.full((img.shape[0],), t_curr, dtype=img.dtype, device=img.device)
img_input = img
img_input_ids = img_ids
if img_cond is not None:
img_input = torch.cat((img, img_cond), dim=-1)
if img_cond_seq is not None:
assert (
img_cond_seq_ids is not None
), "You need to provide either both or neither of the sequence conditioning"
img_input = torch.cat((img_input, img_cond_seq), dim=1)
img_input_ids = torch.cat((img_input_ids, img_cond_seq_ids), dim=1)
pred = model(
img=img_input,
img_ids=img_input_ids,
txt=txt,
txt_ids=txt_ids,
y=vec,
timesteps=t_vec,
guidance=guidance_vec,
)
if img_input_ids is not None:
pred = pred[:, : img.shape[1]]
img = img + (t_prev - t_curr) * pred
return img
End。