
本文提出了一种在DiT框架下的用图像作为控制条件的图像生成框架。相较于之前的方案(比如 controlnet 等),本文的方法优点:
- 更加高效,注入图像条件的分支只增加了 0.1% 的参数。
- 统一的方式处理各种图像条件生成任务,包括基于主体的生成,以及基于边缘,深度等条件的生成。
论文中整理的核心贡献有:
- 提出一种高效的方法,使得在DiT模型中实现图像条件控制,在一个统一的框架内实现了空间对齐和非空间对齐的控制。
- 通过广泛的实验展示了该方法的有效性。文中涵盖了各种控制任务,包括边缘引导生成,深度图生成,特定区域编辑和身份保持生成,在 UNet 和 DiT 上文中的方法均显著优于现有方法。
- 整理了一个数据集:Subjects200K,该数据集包含20万张主体一致的高质量图像数据集。并且提供了一个高效的数据合成流程,为研究社区在主体一致生成任务的进一步探索提供了宝贵的资源。
如何在DiT模型中加入图像控制条件
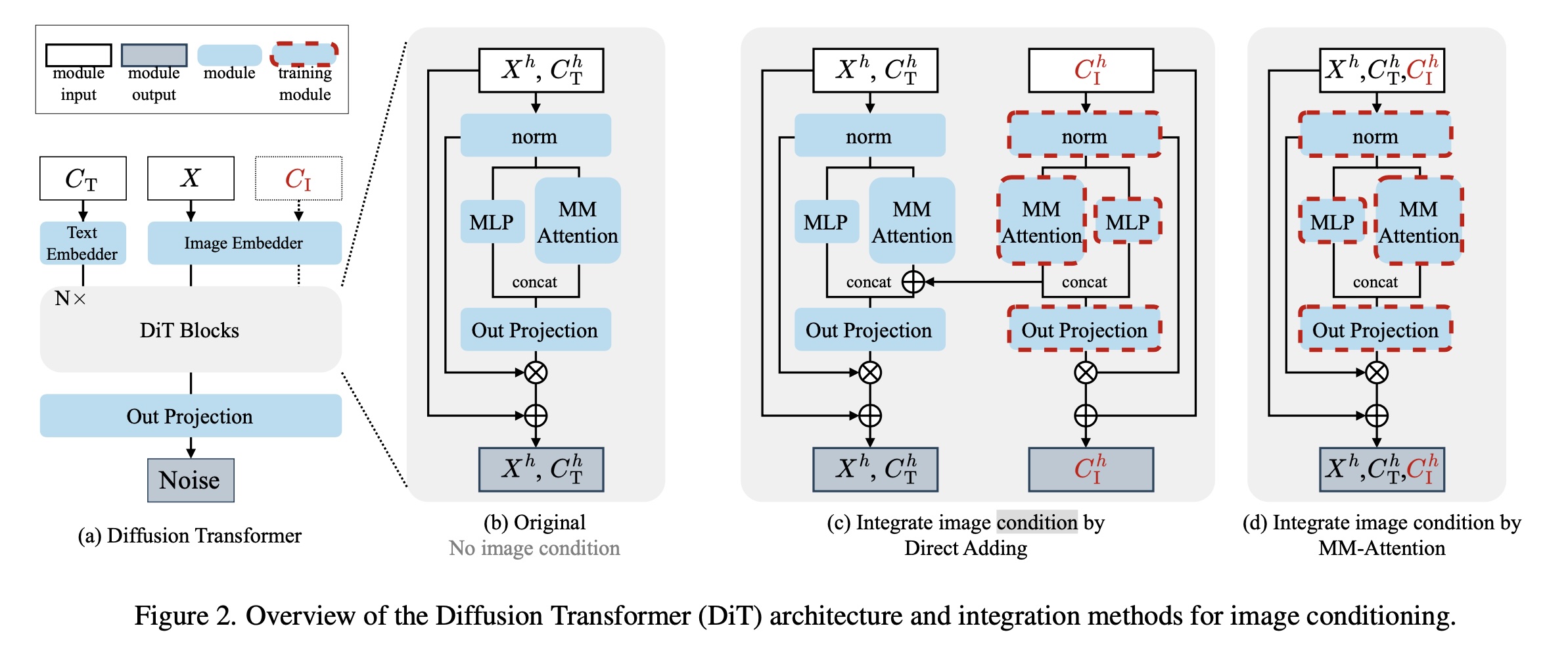
Controlnet 添加 图像条件信号的方式是:$H_{X} =H_{X} +H_{C_{I}}$
这种方式在处理空间位置对齐任务时效果显著,但也面临两个主要限制:
- 在处理非对齐场景时缺乏灵活性;
- 即使在空间对齐的情况下,直接相加隐藏状态会限制token之间的交互,可能会限制模型的性能。
本文采取的方法是上图的最后一列:
$Z = [X;C_{T};C_{I}],$
关于 Adaptive Position Embedding:
在 FLUX.1 的 Transformer 中,每个 token 都会用一个相应的位置编码来编码该 token 的空间信息。对于一个 512x512 的图像,会先用 VAE Encoder 得到隐空间编码,,然后将隐空间编码划分为一个32×32的标记网格,其中每个标记都被分配一个唯一的二维位置索引 (i, j),其中 i, j ∈ [0, 31]。这种索引方案在隐空间中保留了原始图像的空间结构,而文本标记则保持固定的位置索引 (0, 0)。
对于空间对齐任务,我们的初步方法是为条件标记分配与其在噪声图像中对应标记相同的位置编码。然而,对于非空间对齐任务,如基于主体驱动的生成,我们的实验表明,移动条件标记的位置索引可以加快收敛速度。具体来说,我们将条件图像标记移动到索引 (i, j),其中 i ∈ [0, 31] 且 j ∈ [32, 64],确保与原始图像标记 X 没有空间重叠。
关于条件控制强度
通过在 Attention 的时候加入一个 bias(γ) 来控制条件控制的强度。
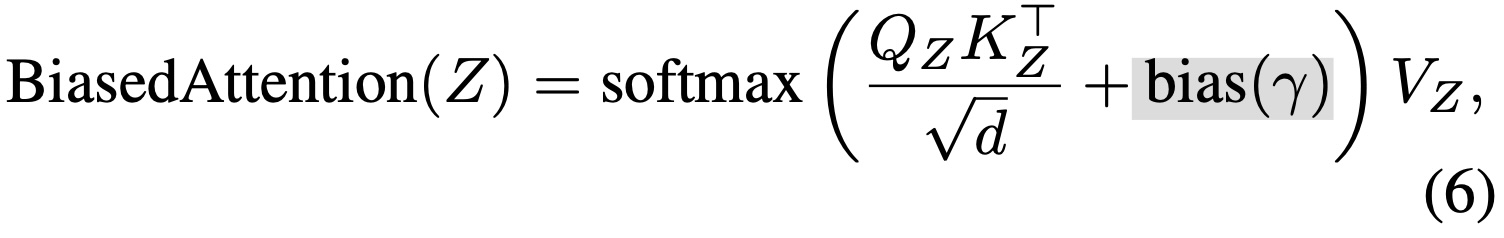
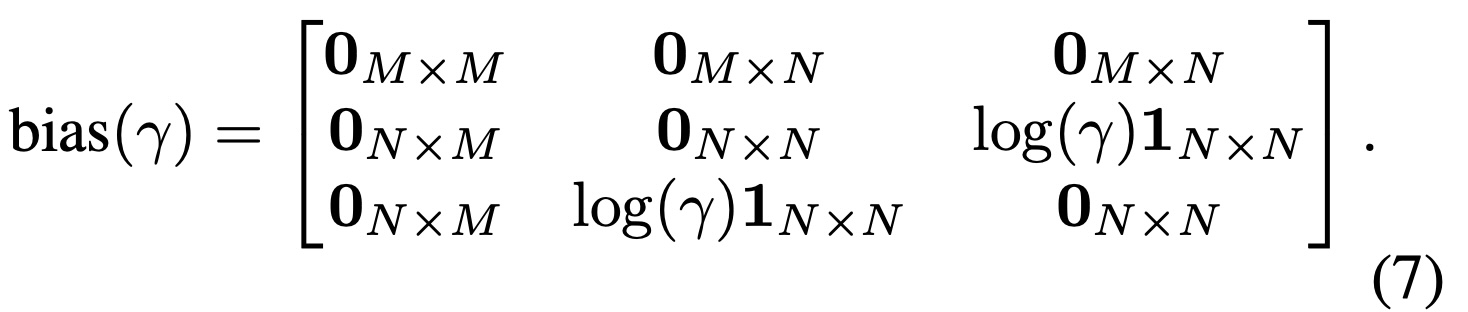
Subjects200K datasets
简单来讲是利用 ChatGPT-4o 生成了20,000个caption,然后利用FLUX生成了200,000图片。
首先本文利用 ChatGPT-4o 生成了 42种不同种类,总共 4696 种物体的caption。
下图是一个样本:

而为了解决主体生成需要的paired数据,本文利用FLUX的特性,利用下面的prompts,可以得到主体一致的图片。

简单来说利用 FLUX 生成一张 1056×528 图,图上是同一个物体分别在左右。是用的时候,把左右分开,然后取中间的 512x512 的部分。
简单在flux上试了下:
Two side-by-side images of the same object: A beautiful Asian woman in a long dress with some flowers on it. Left: She is standing on a beach, full body, looking at the camera, bathed in soft, warm twilight. Right: She is sitting in a bustling urban cafe, which stands out against exposed brick walls, capturing the midday sun through a wide bay window.
生成的结果一致性的确不错。

训练细节:
空间一致的任务(canny, depth)这类任务是放在 FLUX.1-dev 上做的,主体驱动的任务是放在 FLUX.1-schnell 上做的,文中声称这样生成质量会更好。
两种任务都是利用 LoRA (rank=4) 的方式来进行训练的。
结果对比:


效果部分的确不错,特别是主体生成的能力。
以上。