
OmniGen: A new diffusion model for unified image generation. OmniGen no longer requires additional modules such as ControlNet or IP-Adapter to process diverse control conditions.
https://github.com/VectorSpaceLab/OmniGen
https://arxiv.org/abs/2409.11340
简介
本文推出一种新的统一的文生图扩散模型:OmniGen. 相较于之前的 StableDiffusion,或者Flux 等模型, OmniGen有以下特性:
- 统一: OmniGen 不仅能做文生图任务,也可以支持下游任务:比如图像编辑,主体生成,以及视觉提交生成。此外,OmniGen还可以做一些传统计算机视觉任务,比如边缘检测,人体姿态识别。
- 简单:OmniGen 的网络架构非常简单。
- 知识迁移:OmniGen可以非常高效的迁移到未处理过的任务上。
本文的贡献:
- 推出OmniGen,一个全新的统一各种文生图任务的扩散模型。
- 一个新的数据集 X2I, Anything to Image 的缩写。这个数据集包含了各种图像生成任务数据,以标准化的格式存储。
- 在OmniGen上,可以非常高效的把现有能力迁移到新的任务上。
OmniGen
Network Architecture
网络架构上由两部分组成:VAE 和 Transformer 模型。其中 VAE 使用的是 SDXL 的 VAE 模型,训练的时候是被 freeze 的。 transformer 模型采用的是 Phi-3 的网络结构和初始化权重。
网络结构如下图所示:
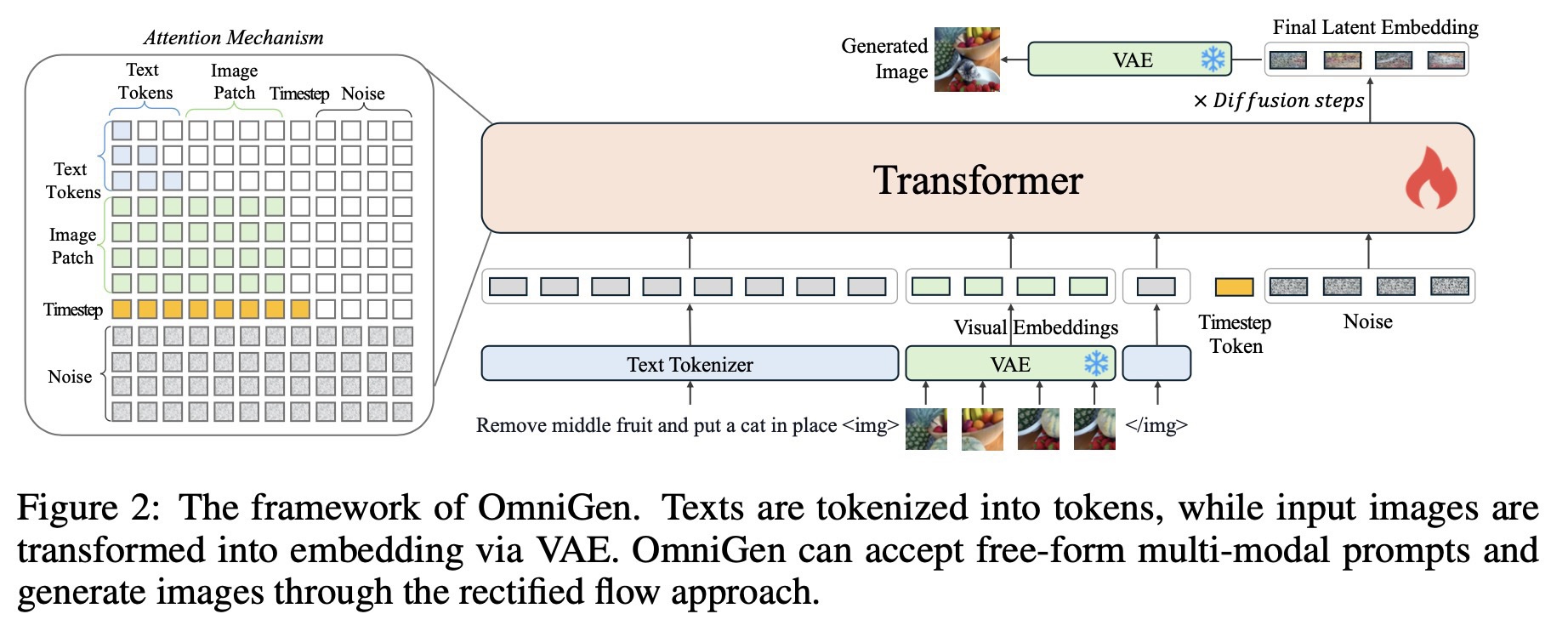
输入格式:
图片:利用 VAE 得到 latent 表示。然后展开成序列。文本和图像嵌入在一起成为一条长的序列。在图像的前后,插入了两个特殊token 和
注意力机制:
如上图左边的 Attention Mechanism 所示,序列中除了 Image Patch 以外的其他元素采用因果注意力机制,图像序列内应用双向注意力机制。
训练管线
选择从小分辨率到大分辨率,渐进式训练策略

数据集
数据集制作部分,介绍下主体驱动生成图像。
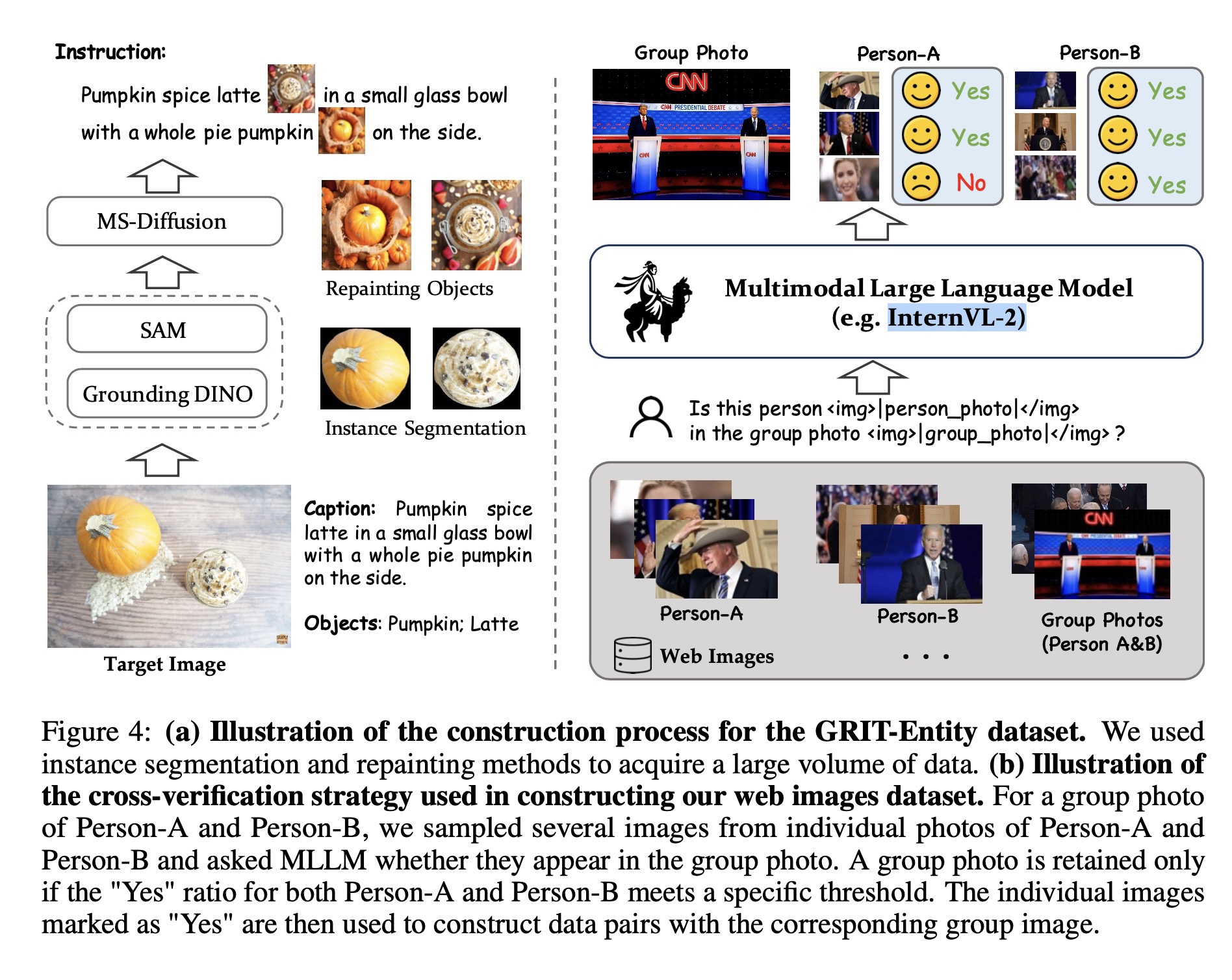
本文制作了两个数据集,分别是通过下图左半部分流程制作出来的 GRIT-Entity数据集,和通过下图右半部分制作而成的高质量领先数据集。
GRIT-Entity:利用 DINO 和 SAM 对图像分别做检测和分割,然后利用 MS-Diffusion 来重绘和增强图片。一共只做了 6M 的数据对。
高质量数据集:只使用 GRIT-Entity 会让模型有比较强的 copy-paste 痕迹,所以本文构造了一个从真实数据中采集多主体的数据集,如下图右半部分所示,对于人物A和人物B的合影,我们从人物A和人物B的单张照片中抽取几张图片,并利用 MLLM 判断他们是否出现在合影中。只有当人物A和人物B的“YES”比例都达到特定的阈值时,才会保留合影。标记为“YES”的单张图片与相应的合影图片构建成一个数据对,用这种方法一共构建了 533,000 图像数据对。
效果部分


可以看到 OmniGen 在各种任务上都有不错的表现。
以上。