前言
这是一篇关于 **SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis 技术报告的中文翻译。
SDXL 是 Stability AI 继 SD 1.5, SD 2.0 之后发布的一个新的文生图模型。目前该模型在 reddit 上讨论还是蛮热烈的。其中一个帖子对比了SDXL 和 SD1.5 的吉卜力风格生成结果:
SD1.5 vs SDXL 1.0 Ghibli film prompt comparison
另外也有一些网友整理出比较全的Prompt测试集,相对系统的对 SDXL,SD1.5,SD2.0 的生成效果进行了对比。
可以看到相较于 SD1.5,SD2.0, SDXL在语义表达,生成图完整性和美观度上均有蛮大的提升。
目前在C站上,以及国内一些类C站的网站上,已经有挺多基于SDXL模型做迭代优化的模型了。SDXL模型在生成方面相较于SD1.5有优势,预计在未来的时间内,更多的人会从1.5转移到SDXL,在SDXL的基础上做模型的迭代优化。
优化内容
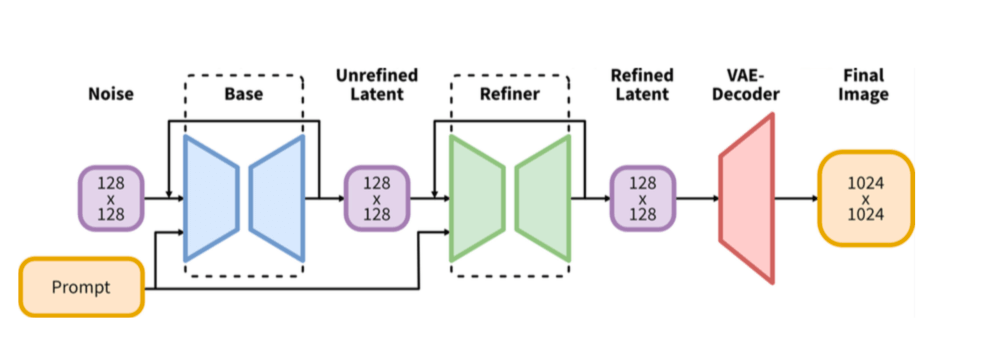
如上图所示,SDXL模型分成两个阶段,分别是 base 模型 和 refiner 模型。
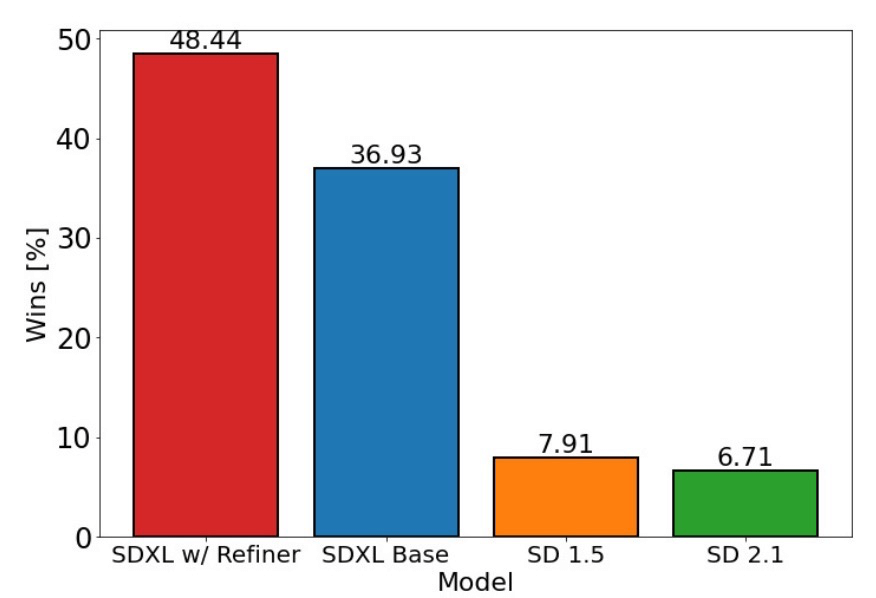
在和SD 1.5 SD 2.1 的比较中, SDXL base模型就有着很大的优势,结合 refiner 模型优势更大。
2.1模型结构的优化

SDXL对网络结构中的UNet, VAE, 以及 CLIP Encoder 均做了相关的优化。
SDXL UNet结构图
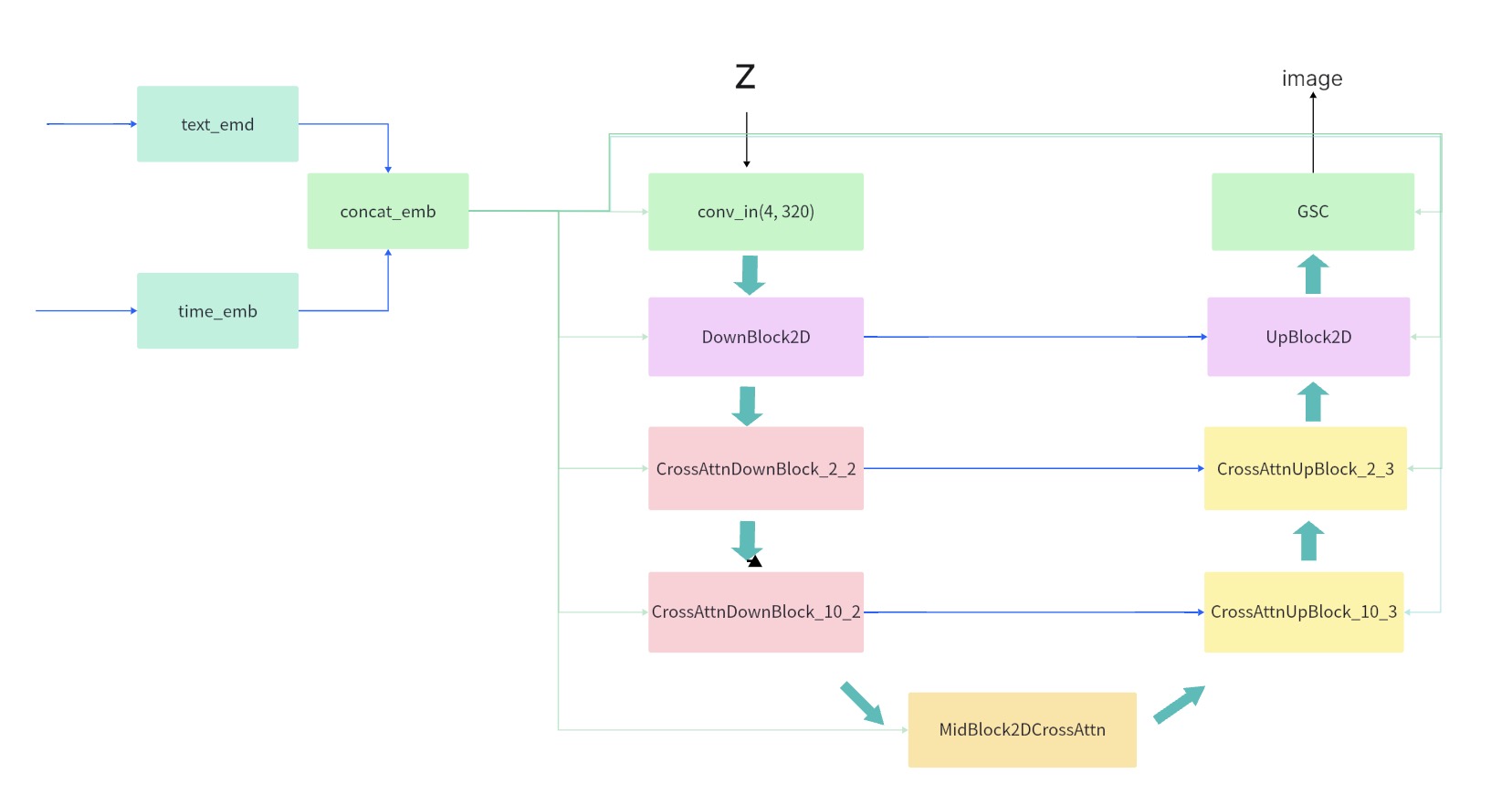
- UNet部分的参数量变成 2.6B,相较于 SD 1.5 的 860M,增大了约3倍。
- CLIP部分,选用 CLIP ViT-L 和 OpenCLIP ViT-bigG
- VAE 部分,XL 重新训练了一个适配 SDXL 模型的VAE。
UNet的参数量主要是增加到网络中的 Transformer Blocks 部分,也就是Self-Attention 和 Cross-Attention 部分。
SDXL UNet 的结构做了相应的改变,从原先的 [1,1,1,1] → [0,2,10],网络从1.5的四阶段变成三阶段,Encoder部分进行了两次下采样。
SDXL 第一个Stage不再使用 Transformer Blocks,而是用的普通的 DownBlock2D,这是为了降低模型计算量,减少耗时。SDXL base 模型生成的图像分辨率是1024x1024, 输入給UNet的latent大小为 128X128X4,SD1.5 这部分的大小是 64x64x4, 如果在第一个Stage就使用 transformer block, 显存和计算量都会比较大。
SDXL 新增的 Transformer Blocks 都放到了 UNet 的第2,3个stage,数量分别是2和10,也就是在feature 宽高比较小的部分使用更多的 transformer block。
Text encoder 部分, SDXL 采用了 参数量为 694M 的 OpenCLIP ViT-bigG, 同时配合 OpenAI CLIP ViT-L/14。使用的时候均是提取text encoder 的倒数第二层,bigG的维度是1280, CLIP ViT-L/14 维度为 748,两者concat后维度是2048。
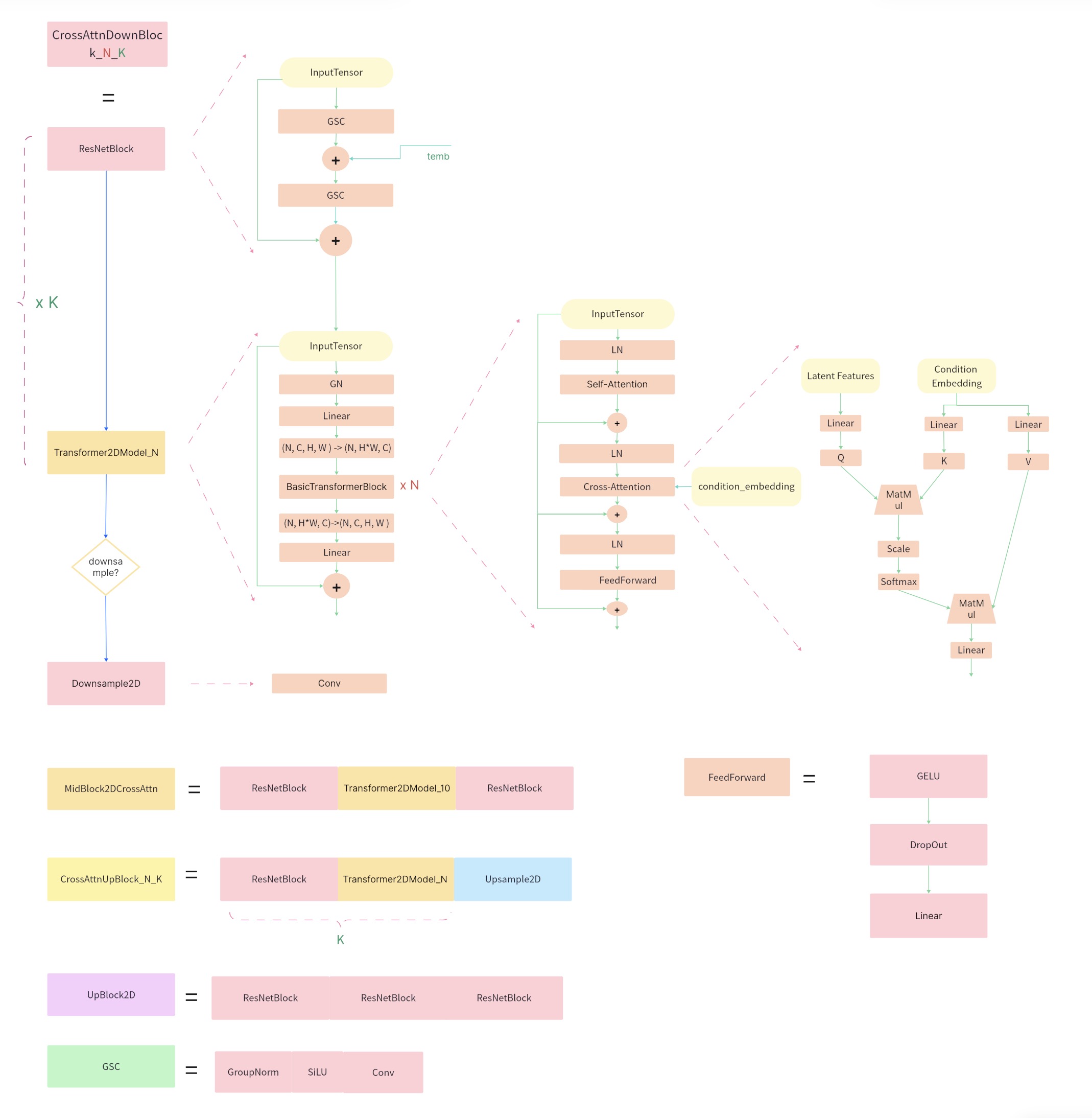
SDXL 网络结构详细图
2.2 微条件注入
SDXL引入额外的条件信息,注入到网络,来解决模型训练中的遇到的一些数据问题。
首先是图像尺寸方面的。
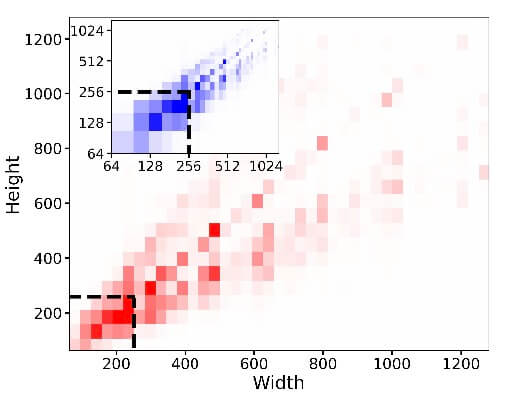
从上图可以看出,数据集中很大一部分的图像分辨集中在256x256附近。SD的训练,一般是先在256x256分辨率上训练,然后再在512x512上训练。在512x512上训楼时,为了保证数据质量,只能选用分辨率在512x512及以上的图片,而这部分数据其实并不多。
为了在训练高分辨率模型的时候有足够的数据可以利用,SDXL在训练的时候,把图像的size当作条件嵌入到UNet中。
方法是将width和height分别用傅立叶特征编码进行编码(和timestep是一样的处理方式),然后把两个编码concat到一起加在time embedding上。
从下图可以看出不同的size下生成图的清晰度有着比较明显的差别。

在训练SD模型时,数据增广部分会对图像进行随机crop,这会导致部分图像裁剪之后不太完整。把不完整的图像送入到网络中训练,会导致训练好的模型,在前向inference的时候生成的图像会出现主体不完整的问题,比如下图的猫头不再图像中,龙的身体不完整。

为了解决这个问题,SDXL采用的方法是把训练时数据增强部分随机 crop 时的左上角顶点坐标作为条件信息嵌入到UNet种,方式方法和前面的 width & height 是一样的,利用傅立叶编码,然后加在time embedding上。
而在推理的时候,我们把这个条件设置成(0,0) 就可以得到一张主体居中的图像。

从上图可以看到,前向输入不同的左上角条件,生成图主体会在对应的区域。
2.3多宽高比训练
在实际使用文生图过程中,会生成不同尺寸的图像。如果用只在512x512, 1024x1024的图像上去生成比如768*1024的图像,生成质量会有所下降。
为了解决可以生成不同宽高比的问题,SDXL把数据根据宽高比分成不同的buckets,单个batch的数据从同一个bucket中采样。,实现多宽高比的训练。
在训练的时候,SDXL同样把宽高比当作一个条件嵌入到UNet中,嵌入的方法和前面的size, offset 一样。
下图是SDXL在训练过程中的用到的宽高比数据buckets。
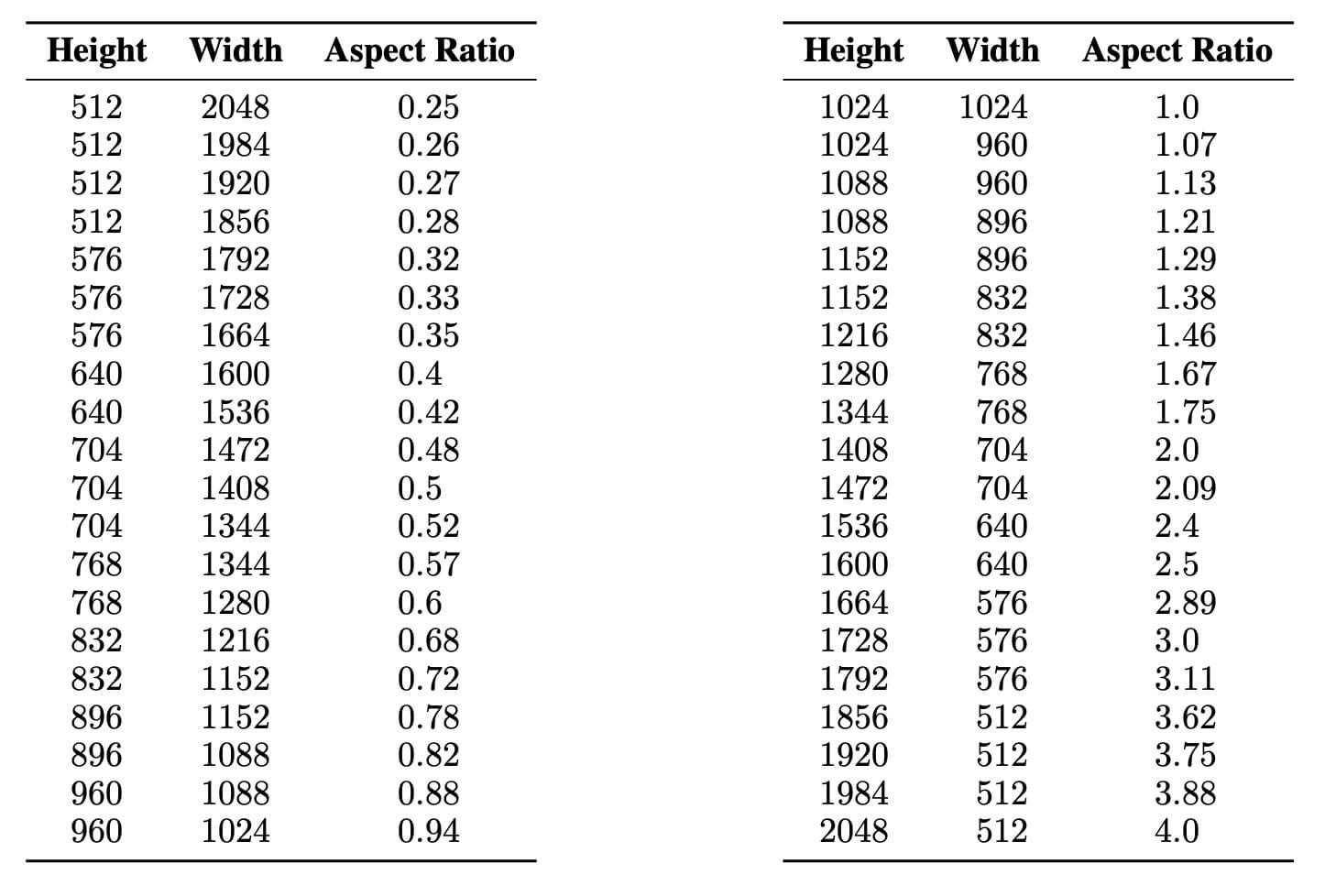
2.4 VAE的提升
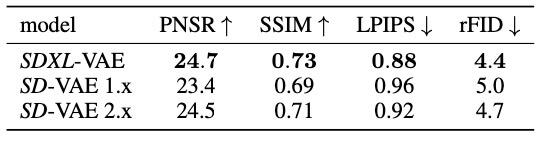
SDXL 专门训练一个VAE,从上图来看 SDXL 的 VAE 在 performance 比 SD 1.5 2.1 用的VAE要好一些。
2.5 整合在一起训练
SDXL通过多阶段来训练模型。首先在一个内部数据集上对base模型进行预训练。过程先训练一个256x256的模型,batchsize=2048,迭代600 000个steps,然后在512x512上迭代优化 200 000 个steps。
Refiner模型
上述训练的SDXL模型在实际使用时有时会生成质量比较低的图像,为了提高模型生成质量,SDXL 在相同的latent space中训练一个新 LDM 模型,该模型的训练数据是经过筛选的高质量,高分辨率的数据。
前向过程中,从SDXL base模型中得到latent code,把这个latent code 作为 refine 模型的UNet的输入,进行去噪得到高质量的生成图像。如下图所示,经过refine模型之后,生成图像的细节有提升。
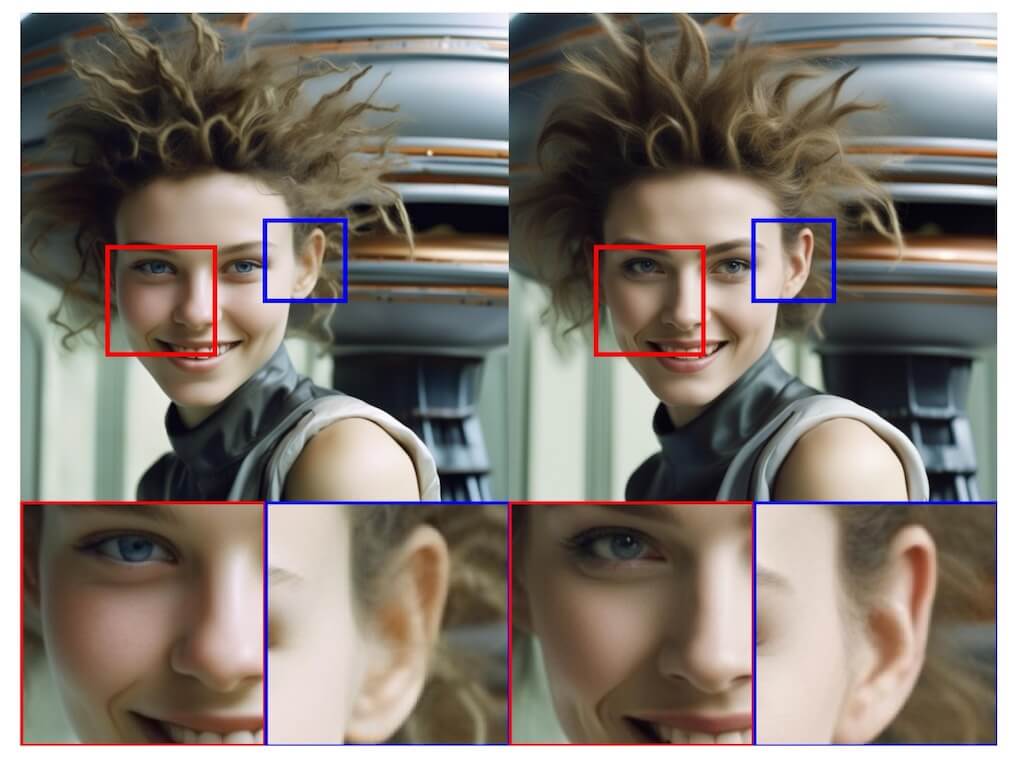
不过从实际测试结果来看,refine模型效果也并不是那么好,是否要用refine模型,有待进一步研究。
局限性
客观来说SDXL相较于SD1.5有着很大的提升,但还是存在一定的问题。下图是一些生成失败的例子。

如上面所示,模型难以生成比较复杂的结构,比如人手。而当prompt中存在多个实体时,生成图会出现属性混乱的问题。另外生成图真实度还无法做到完美,会有一些生成图的痕迹。
未来的工作
- Single Stage:目前采用的是两阶段 base + refine 模型,两个大模型,训练起来比较麻烦,前向部署成本也很高,未来还是更倾向于合并成一个模型。
- 文本Encoder:文本Encoder的能力对文生图模型的performance影响很大,提升文本Encoder有助于提升文生图的生成质量。
以上。