VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time
https://www.microsoft.com/en-us/research/project/vasa-1/
微软的一篇关于 talking head 的工作,叫:VASA-1。VASA-1 是利用一段音频和一张照片,生成一段该照片说话的视频。
他的核心贡献是:
- 结合 Diffusion 范式和 transformer 网络框架,将其利用在 talking head 领域。
下图是简介:

Training and Testing
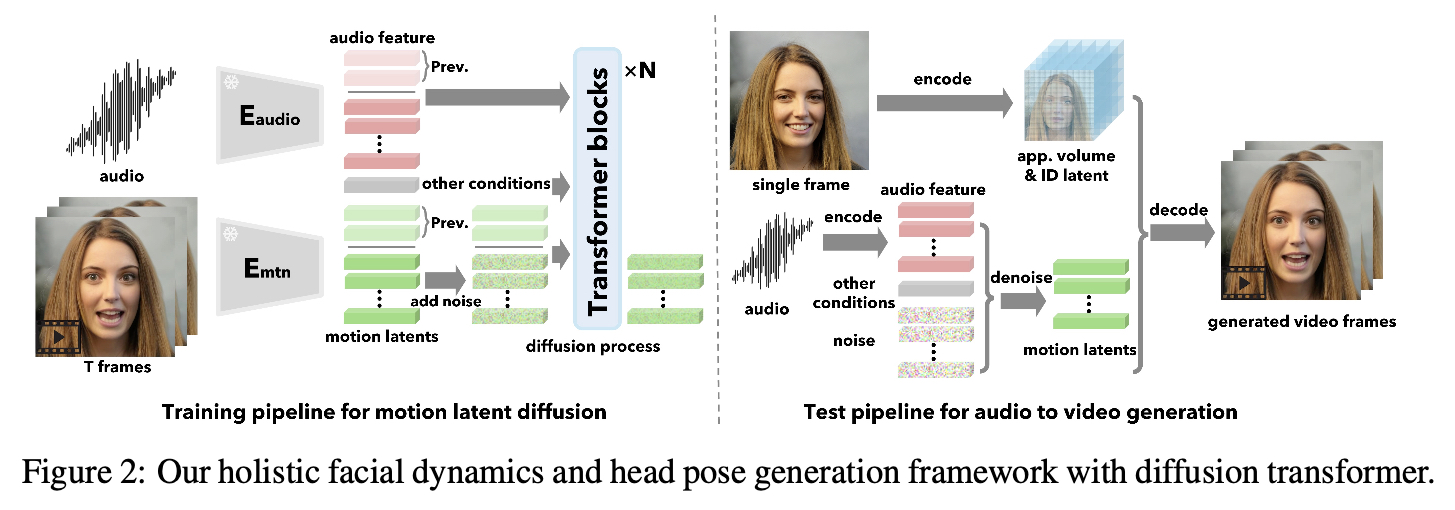
从上图可以概括来讲:
- 模型框架叫:motion latent diffusion。它是基于 transformer-based,结合 diffusion 范式(数据处理方式,loss)
- 模型的生成目标是:目标条件下的人脸的 motion latents
- 预测的时候,利用训练好的 motion latent diffusion 得到 motion latents,结合 single frame 的 app volume 和 ID latent,decode成视频帧。
细节上:
在训练的时候,会先对一段视频做音频和视频帧的处理:
- $E_{audio}$:音频特征提取;文中利用的是 audio2wav 预训练好的模型。
- $E_{mtn}:$ 表情动作特征提取;文中是基于另外一篇工作:MegaPortraits: One-shot megapixel neural head avatars,利用训练好的 MegaPortraits 的 motion encoder 来提取视频帧的 motion latents。
- 本文对 MegaPortraits 的模型进行优化,主要是 loss 设计上的,后面会提到。
motion latent diffusion 训练 pipeline 很清晰明了:把 音频特征,motion latents 以及 other conditions,拼成一个大的 token,利用 transformer 结构,结合 diffusion loss 进行训练,生成目标 motion latents。
预测部分:
app.volume 和 ID latent,是利用 MegaPortraits : One-shot megapixel neural head avatars 中的方法,获取的。
其中涉及到如何把一张人脸进行属性解耦,具体是采用MegaPortraits : One-shot megapixel neural head avatars中的方法, 如下图:
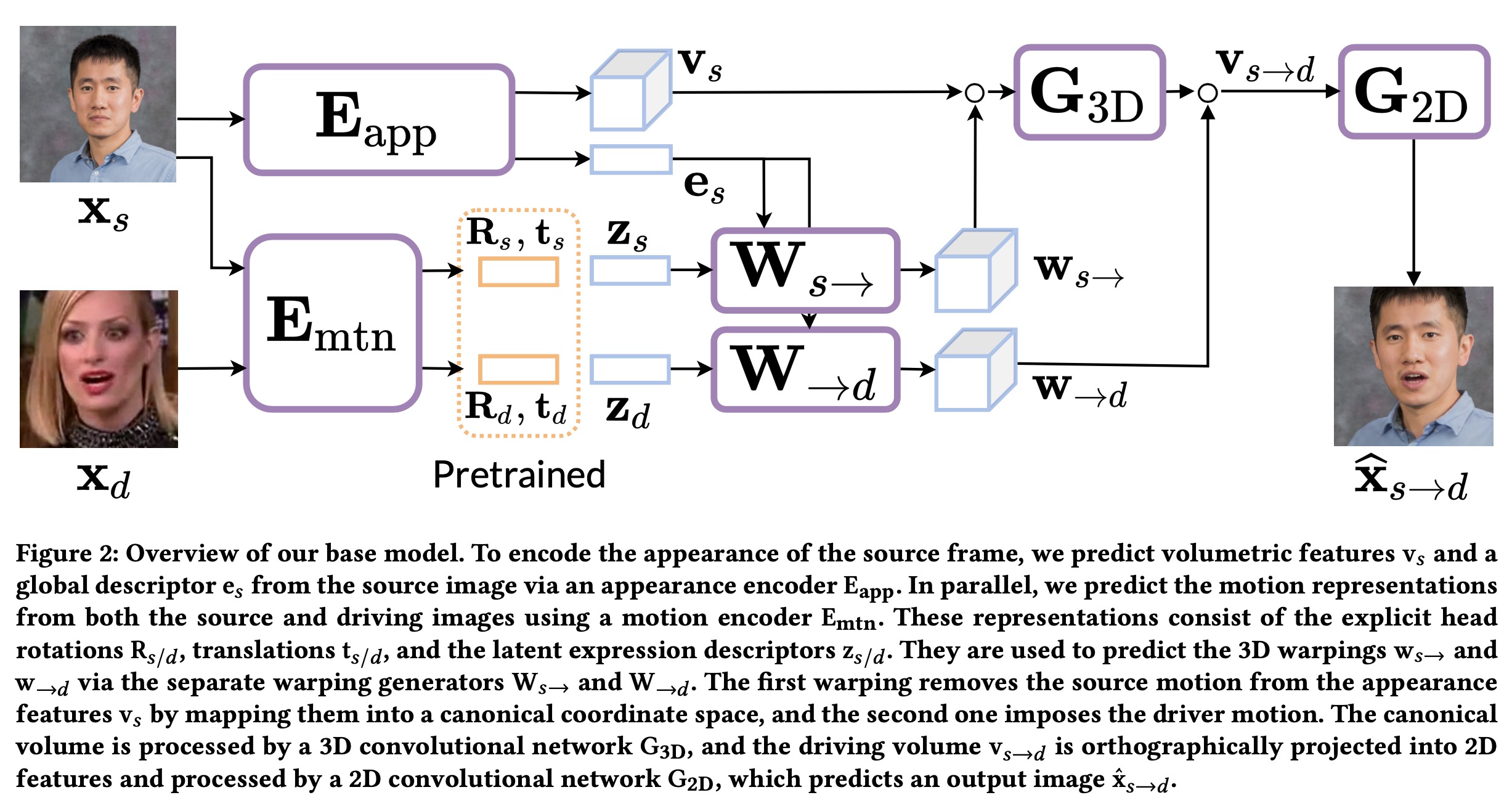
简要介绍 MegaPortraits 的训练思路:
- 训练第一阶段,从同一段视频中采样 $x_s$ 和 $x_d$ 两帧视频帧,利用 $E_{app}$ 提取 $v_s$ 和 $e_s$. 利用 $E_{mtn}$ 分别提取 $x_s$ 和 $x_d$ $z_s$ 和 $z_d$。训练把 $x_s$ 的 motion 去掉,并投射到一个标准坐标在,然后在诸如 $x_d$ 的 motion。

- 此外推理时,source 图和目标动作图非同一个视频,只利用上述同视频不同帧训练,泛化效果不好。MegaProtraits 加入 cycle loss来优化这个问题。具体来说 source帧和目标帧从两个不同的视频中采样,并利用cyclegan的那种方式来进行 loss 设计和训练。
Loss
文中指出 MegaPortraits : One-shot megapixel neural head avatars 解耦效果还不够好,所以在此基础上,加了两个loss来进行优化。
$I_i$ and $I_j$ 是同一段视频中的不同两帧
定义

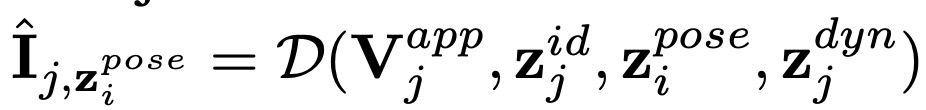
$\hat{I}{j,z^{pose}{i}}$ : 表示 j apply i 帧的 pose;
$\hat{I}{i,z^{dyn}{j}}$ 表示 i apply j 帧的 dyn;
目标状态的id,pose 和 dyn均一致, 然后最小化 $\hat{I}{j,z^{pose}{i}}$ 和 $\hat{I}{i,z^{dyn}{j}}$ 。
为了进一步加强ID:
$I_s$ 和 $I_d$ 为一段视频的两帧
定义

上述公式 是利用 s 帧 的 id ,volume 和 d 帧的 pose和dyn ,也就是把 d 帧的motion 迁移到 s 帧,对迁移后的结果和 $I_s$ 算人脸 cosin-similarity。
利用这两个 loss,对 One-shot megapixel neural head avatars 进行训练优化,得到更好的$E_{app}$ 和 $E_{mtn}$。
条件信号: Conditioning signals
$C = [X^{pre}, A^{pre}; A, g, d, e]$
Classifier-free guidance (CFG)

g: the main eye gaze direction
d: head to camera distance
e: emotion offset e
生成结果:


问题
(1)部分视频生成的人脸表情比较僵硬,看起不真实
(2)生成效率还是不够好,目前还没有办法在实时通信场景下应用
以上。