Text-to-image Diffusion Models in Generative AI: A Survey
本文是关于 Text-to-image Diffusion Models in Generative AI:A Survey 的翻译和摘要。
自2021年2月 OpenAI 推出 DALL- E 之后,文生图进入了AI研究人员和大众的视野。伴随着22年 DALL-E 2, Imagen 等 paper 的发布,文生图模型的生成效果突破了临界点,达到了可商用的程度,商业价值的提升也让其热度不断攀升。
开源社区推出的StableDiffusion让广大的开发者可以基于该模型做各种各样的 finetune 和修改,创造出了非常多效果惊人的模型。
文生图算法研究是计算机视觉中的经典问题之一。如下图所示,在21年之前,这一领域前几年是通过GAN(对抗式生成网络)网络框架来进行相关探索。21年,OpenAI release了DALL-E,正式把文生图算法带入大模型领域。
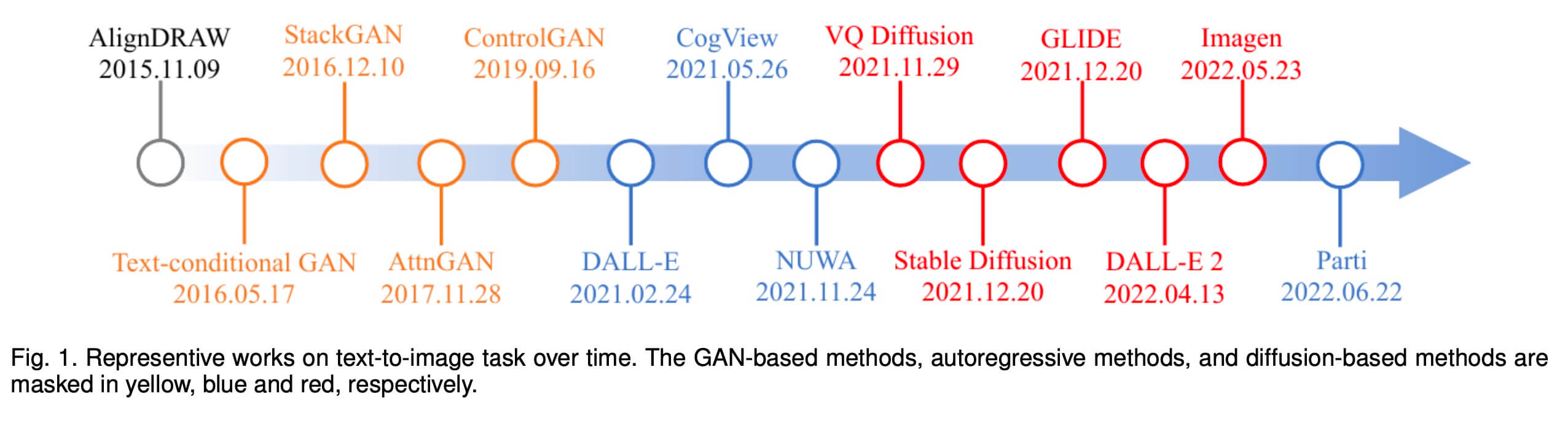
文生图大模型分成两个不同的技术流派,一种是以 DALL-E 为首的基于 transformer 框架的自回归模型,一种是以 DDPM 为首的 diffusion 模型。共同点是两种方案都需要海量的数据,以及比较大网络参数模型。
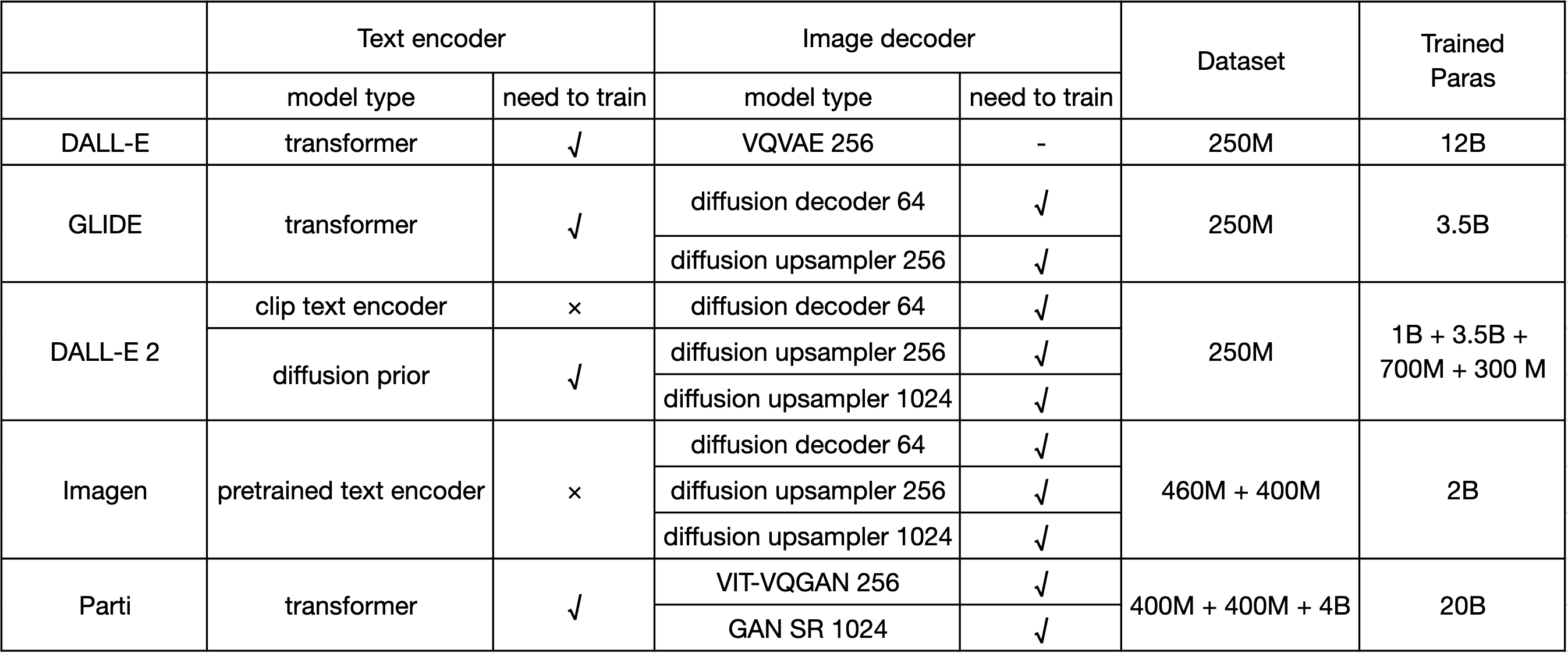
下图是一些主流模型的训练数据量和网络参数大小对比:
自回归模型
图一中蓝色部分是属于基于 transformer 的自回归模型,从当前的发展趋势来看是明显不如 Diffusion 模型一派。
但基于 transformer 的 DALL-E 是文生图大模型开山之作,这里介绍下 DALL-E 的相关工作。
DALL-E 的网络结构如下:
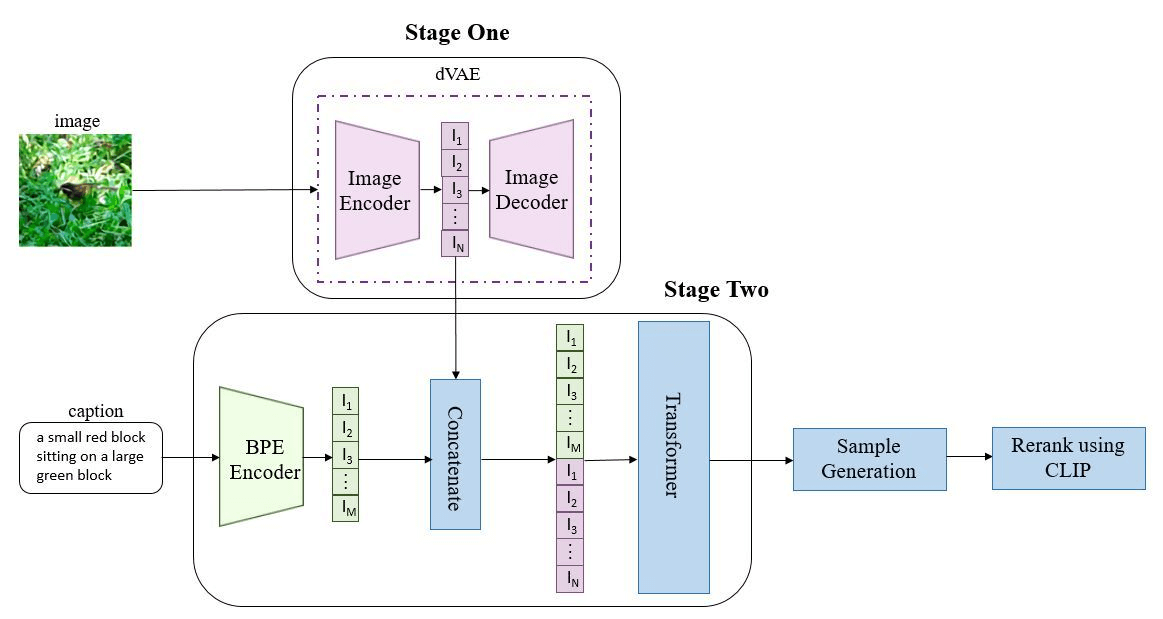
DALL-E 的核心思想是,文本 token(256) 和图像 token(1024) concat 成一个数据序列,通过Transformer进行自回归。
国内的CogView,Google 的 Parti 都属于这一类。
不同的地方在于有些在文本输入的地方加入一个预训练的语言模型,对文本做embedding
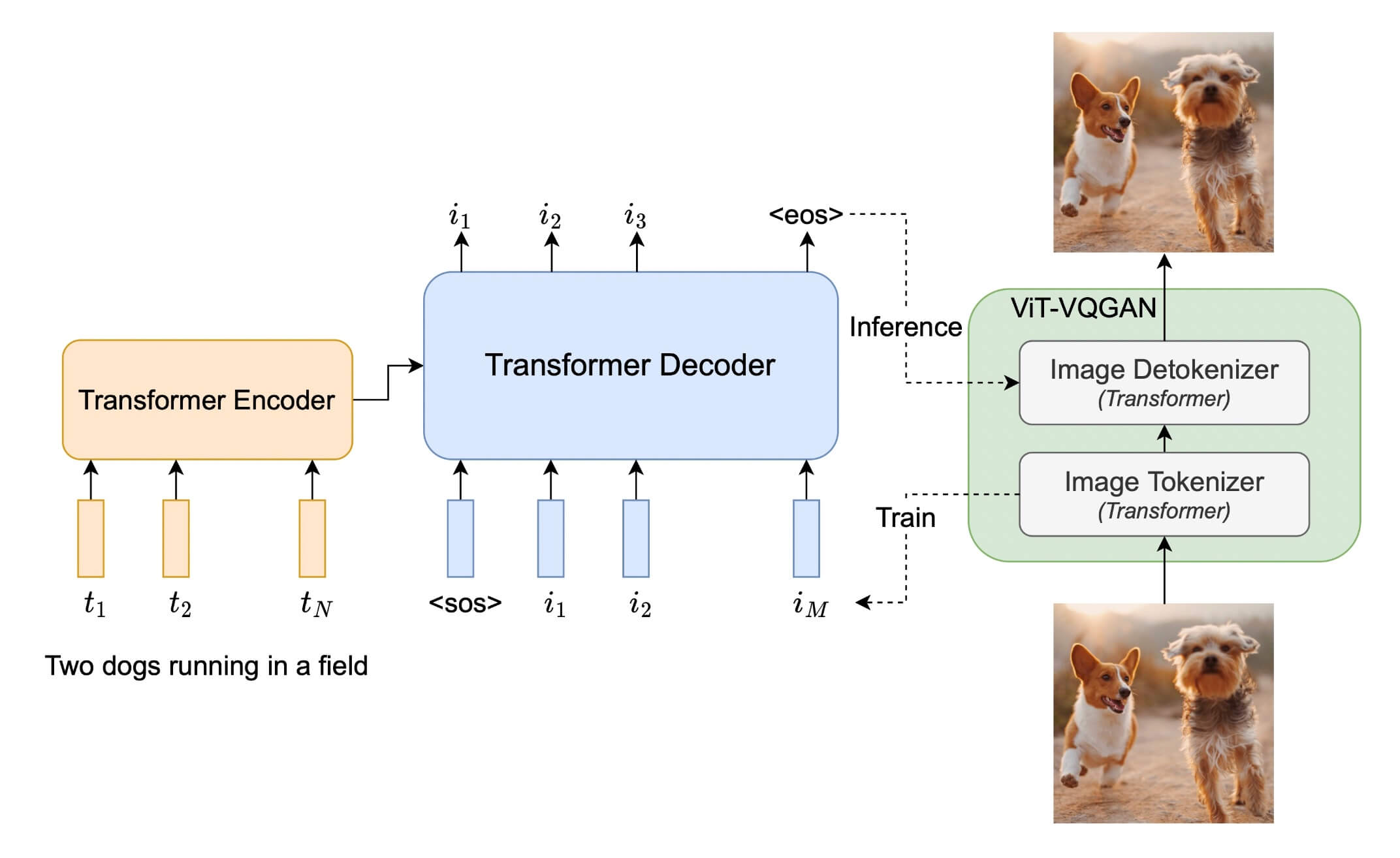
Parti 网络结构图:
扩散模型
扩散模型,也称作扩散概率模型。扩散模型第一次被大家关注到是通过论文 Denoising Diffusion Probabilistic Models,缩写是 DDPM。DDPM 的生成结果在多样性,和真实性上表现很好,但 DDPM 在量化指标上并没有超过 GAN。而 OpenAI 在21年5月发表的论文 Diffusion Models Beat GANs on Image Synthesis,该论文在 DDPM 的基础上做了一系列的改动,让 Diffusion 模型生成结果的各项指标第一次让超过了GAN。
而 DDPM 也不是凭空出现的,DDPM 也得益于两个前期的工作尝试:2019年的基于分数的生成模型 和2015的扩散概率模型DPM。
Diffusion Probabilistic Models (DPM) - 扩散概率模型
生成式模型本质上是一组概率分布。如下图,我们利用左边的训练数据集 $p_{data}$,去构建右边的生成式模型。在概率分布中,所谓的生成式模型就是找出一个分布 $p_θ$ 使得它离 $p_{data}$ 距离最近,这样从 $p_θ$ 上采样新样本时,其结果就会和训练集中数据分布相似。
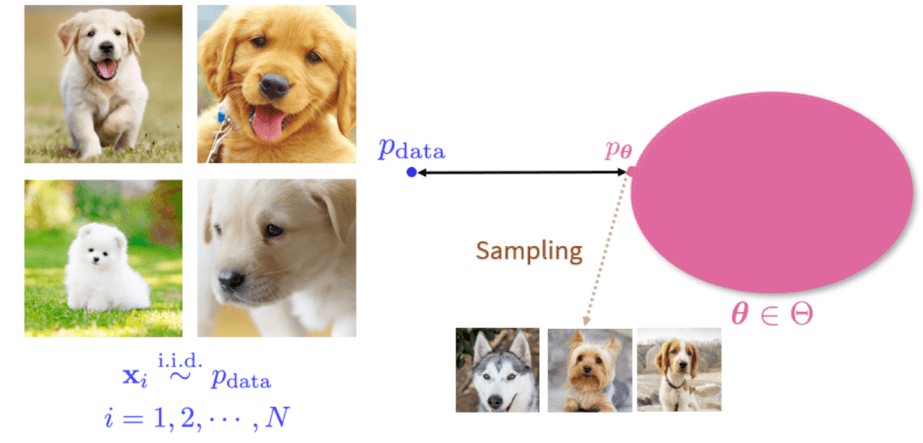
但图像的维度很高,$p_{data}$ 的形式非常复杂,很难遍历整个空间,而我们能观测到的数据也是有限的。直接利用 $p_{data}$ 去构建 $p_θ$ 非常困难。
为了解决上述问题,DPM 定义了一个前向(推理)过程,其核心贡献是:**将复杂数据分布转换为一个简单的分布。**具体来说,我们对训练数据 $p_{data}$ 不断加高斯噪声,使得它最终变成一个纯噪声分布 $N(0, I)$。
这里举一个瑞士卷例子,瑞士卷初始形状为一个二维联合概率分布 $p(x, y)$,通过扩散过程 $q$ ,在样本点上加噪声扰动,使得瑞士卷不断向外扩散,最终变成一个完全无序的噪声分布。
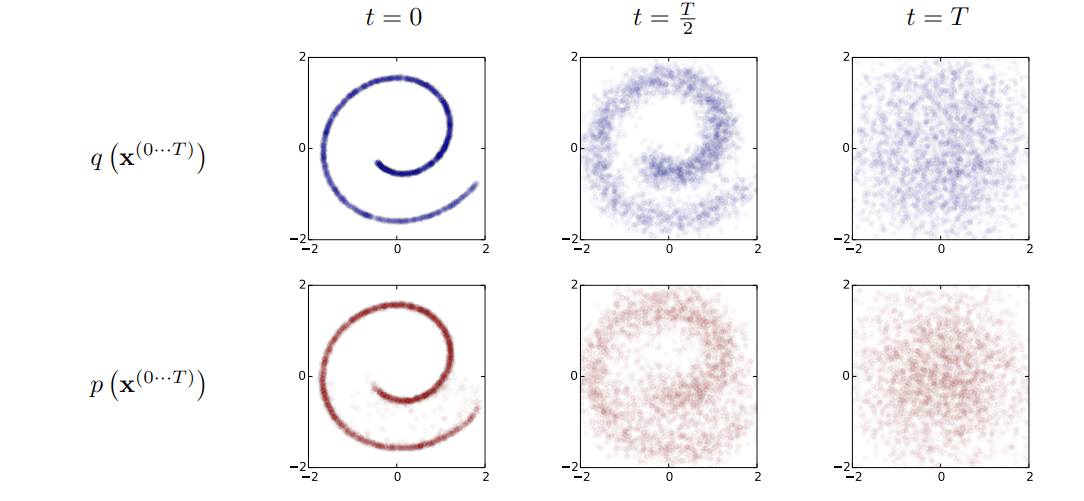
而把上述扩散过程进行反转,利用神经网络去学习右边噪声到左边瑞士卷的映射。利用学习到的映射可以将一个噪声分布 $N(0, I)$ 不断去噪,生成新的符合训练集整体分布特征的的样本。
DDPM 如何进行图像合成的?
DDPM 是参数化的马尔可夫链,在前向的时候,把噪声通过训练好的模型转换成图像。
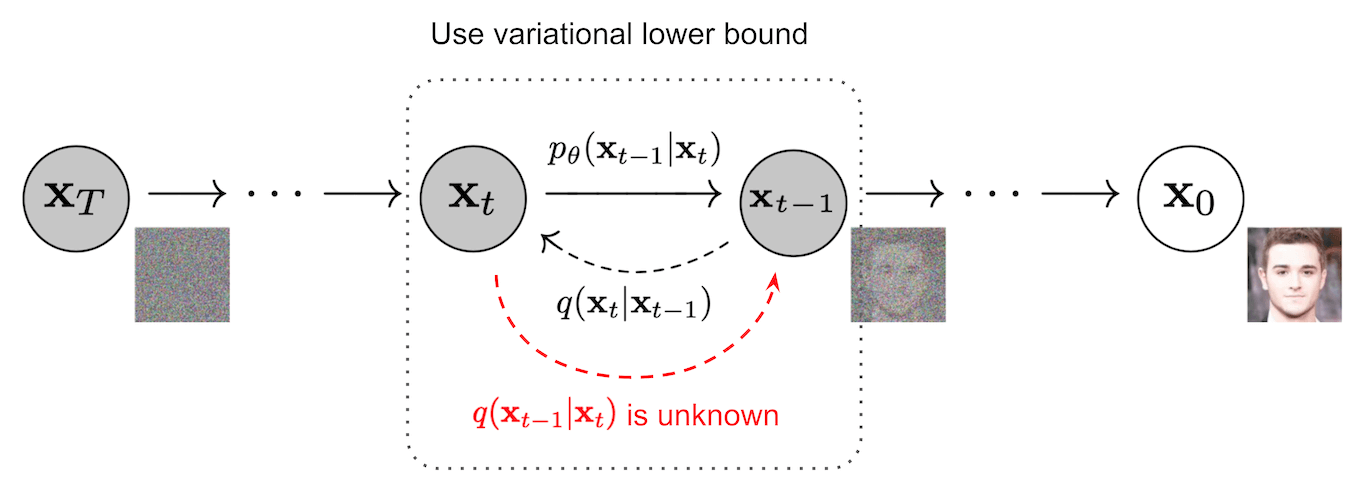
Classifier-free guidance
DDPM 后续发展有两个非常重要的节点
(1)Diffusion Models Beat GANs on Image Synthesis ; 这个工作在量化指标上(如 FID) 第一次超过了 GAN 网络。文章来自于OpenAI,作者发现通过在 diffusion 网络生成过程中,加入一个类别 label,会让模型结果得到显著提升。这篇工作,需要训练一个辅助分类器,且 diffusion 网络无法很好的生成分类器不支持的类别图像。
(2)Classifier-Free Diffusion Guidance; 受上述(1)的启发,提出 classifier-free 的方法。classifier-free 的方法不需要辅助分类器。训练的时候,classifier-free 方法在同一个模型中训练 unconditional score estimator $ε_θ (x)$ 和 conditional score estimator $ε_θ (x, c)$ 两种情况。 $\tilde{ε}_θ(z_λ, c) = (1 + w)ε_θ(z_λ, c) − wε_θ(z_λ)$
文生图模型
基于 diffusion 模型的文生图发展到目前为止,也可以分成两派,分别是 pixel space 和 latent space。所谓 pixel space 指的是在像素维度做 diffusion 生成图片;latent space 指的是在 latent 空间,对 latent code 做 diffusion 操作,最终会使用一个 decoder, 把经过 diffusion 的latent code 转换成图像。
Pixel space 的工作有 OpenAI 的 GLIDE,和 Google 的 Imagen。
Latent space 的工作有 OpenAI 的 DALL-E 2 以及 Stable Diffusion(latent diffusion)。
GLIDE
借助于 Classifier-free guidance 两篇工作,OpenAI 于21年11月发表了 GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models 工作。简单来说,这篇工作把 classifier-free 工作中的 condition 从类别 label 换成 Text(文本)。GLIDE 是第一个可以通过文本来引导 diffusion 网络生成图片,达成 diffusion 网络文生图的 milestone。GLIDE 的工作在 FID 和主观评测上均超过了 DALL-E。
Imagen
Google 于22年5月发表了 Imagen (Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding) 模型,其效果是很不错的。
Imagen 网络结构下图所示。
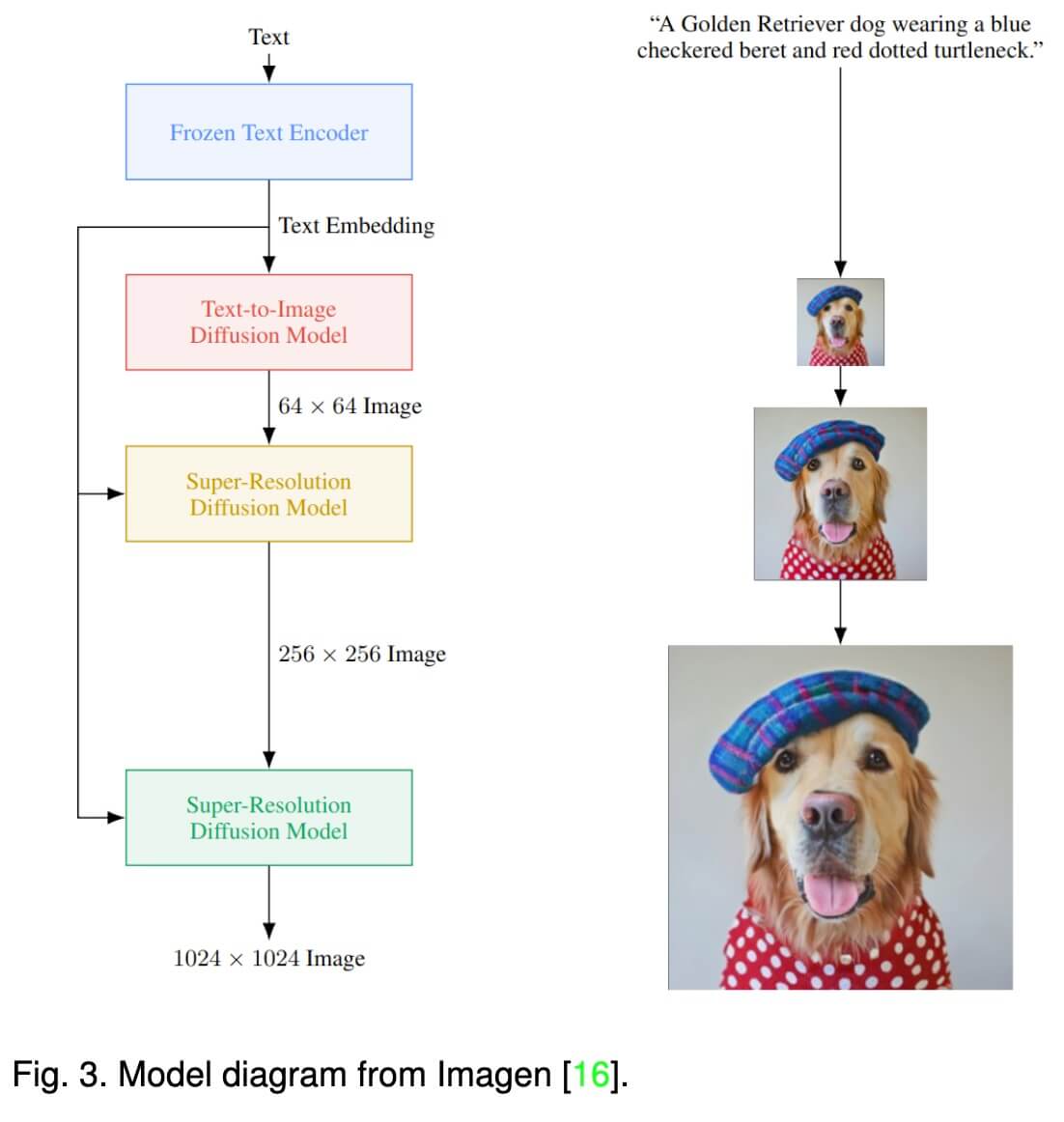
和 GLIDE 不同的地方在于,Imagen 中对文本的处理采用的是类似 T5 这种大模型,在训练的过程中利用 T5 对文本提取embedding,然后把文本 embedding 送给 diffusion 进行图像生成。过程中文本模型是锁死的,不参与训练。而 GLIDE 中,文本的 embedding 网络是一起参与训练。
用预训练的文本模型的好处,如 BERT,GPT, T5 这类文本模型,他是 Text-only 模型,其数据量获取难度远小于 CLIP 那种需要 image-text paired对数据,量级也会比后者大得多。
另外 Imagen 论文中提到,对比增加语言模型(T5)的大小比扩大 Imagen 中的扩散模型大小更能提高图像保真度和图像-文本对齐。
Stable Diffusion: 隐空间生成里程碑工作
Stable Diffusion 是基于 High-Resolution Image Synthesis with Latent Diffusion Models 研发出来的。
Stable Diffusion 网络结构如下图所示:
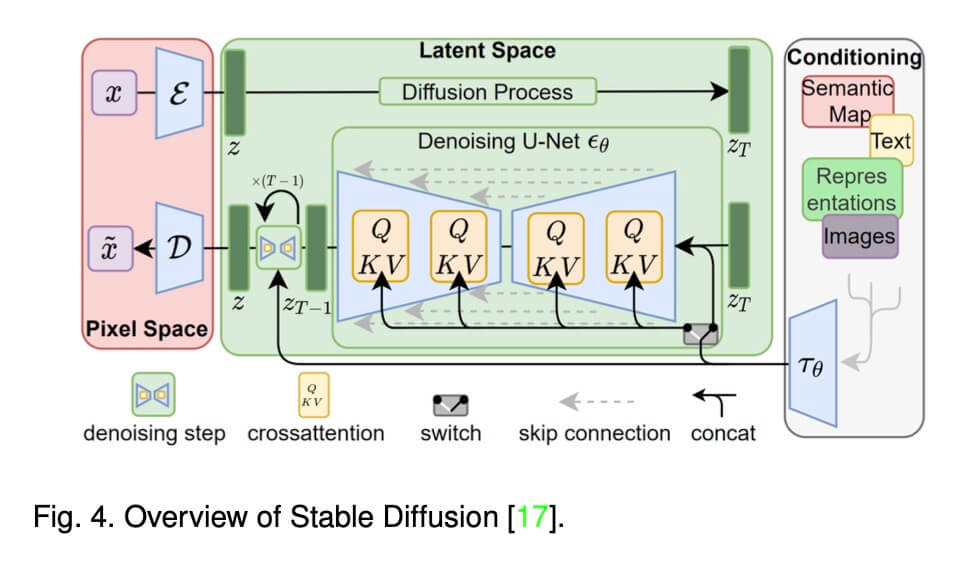
Stable Diffusion 网络可以分成三个部分,左边的第一部分,通过一个 VQVAE 网络,先把图像编码到 latent space。中间部分是一个 diffusion 模型,在 latent 空间做diffusion。右边是 condition 部分,比如文本,通过预训练模型CLIP,提取出embedding后,利用 cross attention 机制嵌入到中间的 diffusion 过程。
需要注意的是 Stable Diffusion 的 latent 空间一般为 4x64x64, 大小要小于像素空间,在 Diffusion 特有的机制下,对计算量的减少是显著的。
DALL-E 2
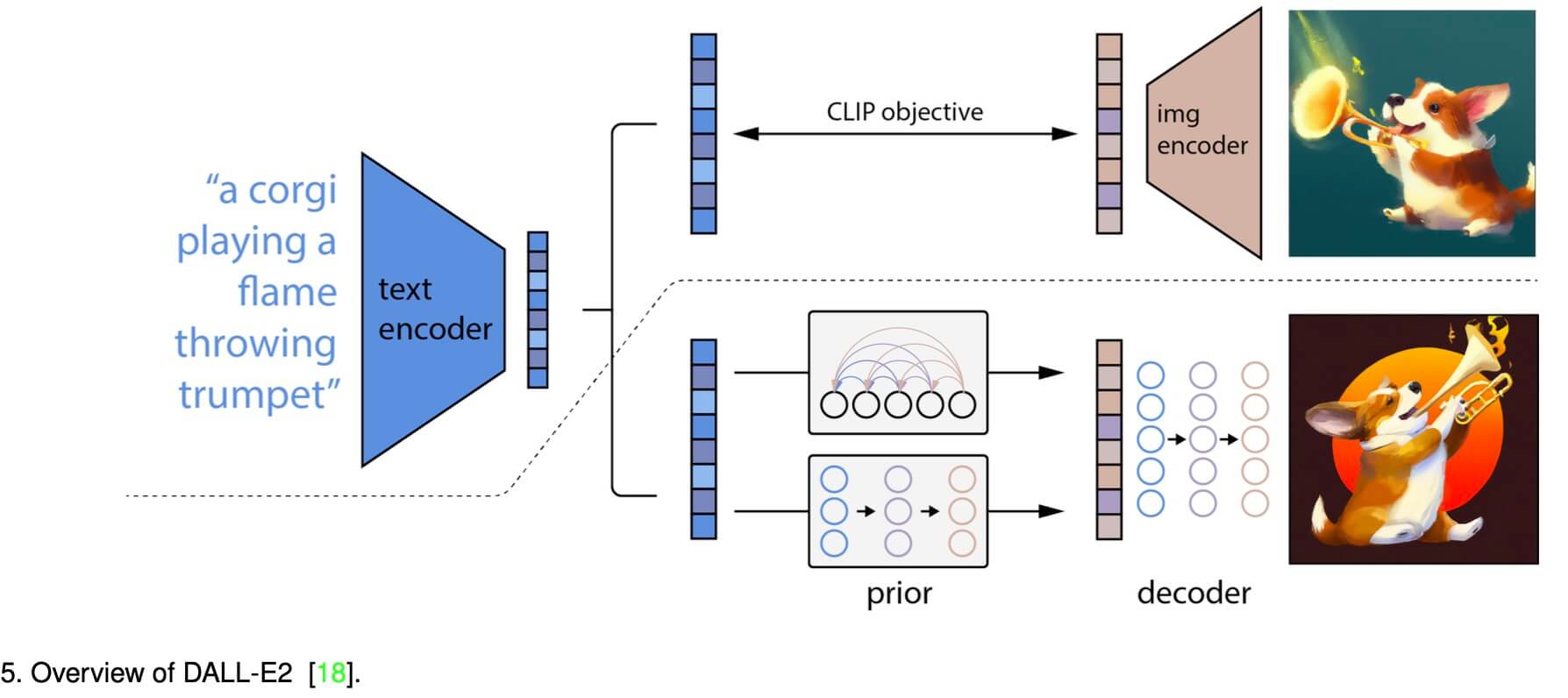
DALL-E 2 是 OpenAI 22年4月发布一个新的文生图模型,OpenAI 在 DALL-E 2中改用了 Diffusion模型作为生成网络基架。 DALL-E 2 模型分成两个部分,第一部分,利用 CLIP 网络,对一组 Text-Image 训练集中的文本和图片分别提取 TextEmbedding 和 ImageEmbedding。训练一个 Prior 模型,这个 Prior 模型,负责把 TextEmbedding 映射到 ImageEmbedding。利用映射得到的 ImageEmbedding 过一个同样是 Diffusion 结构的 Decoder 生成图像。
DALL-E 2 论文中提到,如果没有 Prior 模型,直接用 CLIP 的 TextEmbedding 去和 Diffusion UNet 做 cross attention,网络生成质量会大幅下降。
Diffusion 生成效果优化
Stable Diffusion 的开源使得大家都可以去做文生图大模型,后面针对 Diffusion 模型结果的优化,绝大多数工作都是基于 Stable Diffusion。这里也凸显出了开源的力量。
关于 Stable Diffusion 的效果优化,主要围绕着一下几个方面:
- 个性化物体的生成。
- 控制生成图的内容。
个性化内容生成
个性化内容有三个工作,分别是
Text-Inversion:An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Dreambooth:DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
Lora:LoRA: Low-Rank Adaptation of Large Language Models
三者都是为了让 Diffusion 具备生成一类新概念的能力。下面这张图很好的展示三者之间的差别:
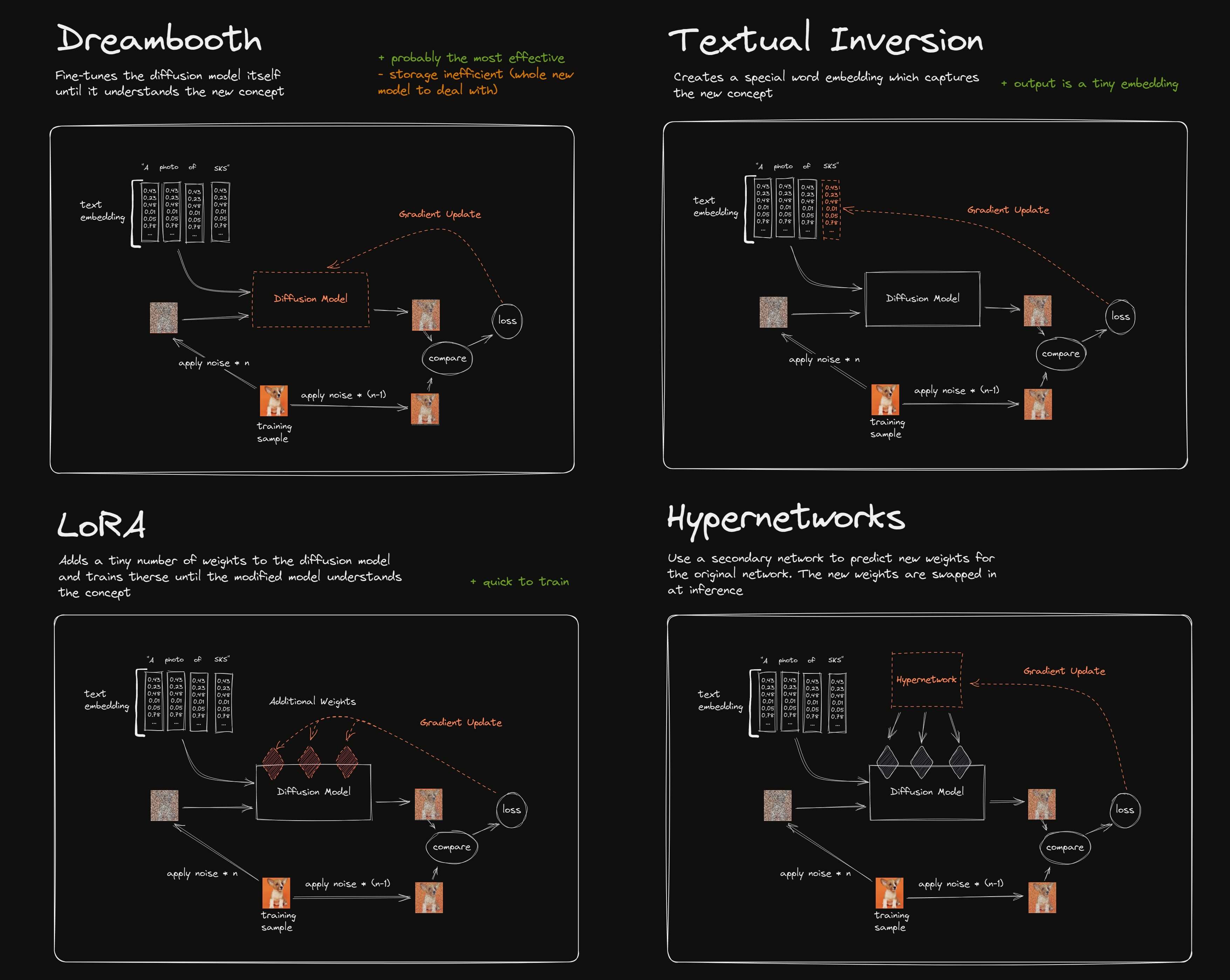
Textual Inversion:在text embedding 部分注册一个特别词,比如 ‘sks’, 网络训练的过程中,是优化 ‘sks‘ 对应的 embedding。
Dreambooth: 和 textual inversion 一样,也定义一个 ‘sks‘ 单词,但是在训练过程中是优化整个 diffusion Unet 网络。
LoRA: 也需要定义一个 ‘sks‘ 单词,LoRA会给网络主干部分加一个 addition 网络,相当于一个外挂,训练过程中只优化 addition 网络。
从目前开源社区的热度来说,LoRA 的热度是最高的.LoRA 相较于 Text Inversion,个性化物体生成质量会更好,相较于 dreambooth, Lora 的模型大小只有 150M。Dreambooth 需要 finetune 整个网络,所以每个个性化任务模型都是 5G,LoRA 虽然每个个性化任务也需要单独 finetune,但网络大小只有 150M 左右,。此外多个 LoRA 还可以联合使用,有一定的组合能力。
控制生成图的内容
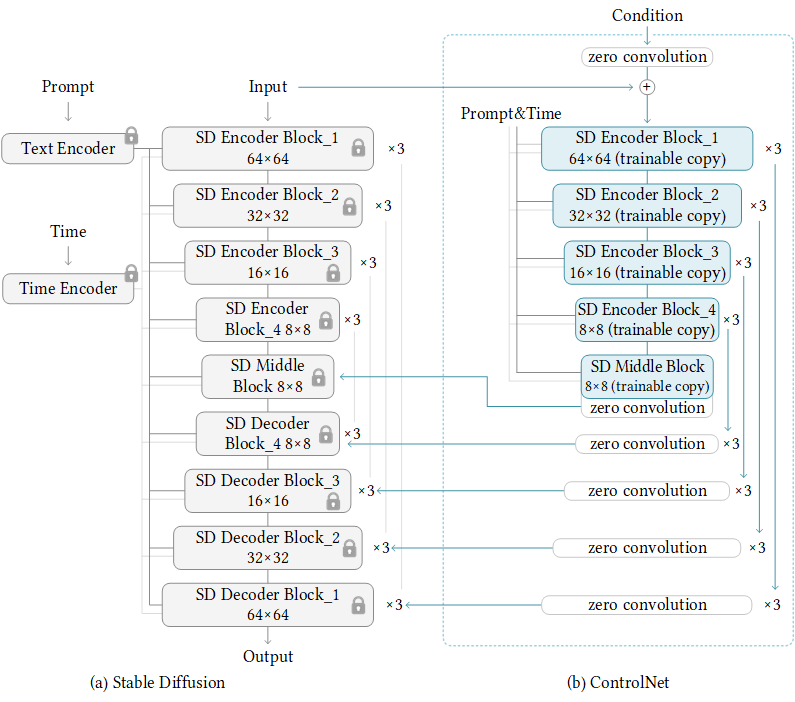
基于 Diffusion 模型控制生成图内容,目前最重要的工作是 ControlNet: Adding Conditional Control to Text-to-Image Diffusion Models
ControlNet 的网络结构如下,他是在 Stable Diffusion 基础上完成的。下图左边是原生的 Stable Diffusion 网络结构,右边是 ControlNet。右边的网络是 condition,网络结构整体层级和 Stable Diffusion 是一样的,其中 Encoder部分直接复用 Stable Diffusion 的 Encoder 结构和 weights,Condition 的特征会通过卷积叠加到 SD 的 Decoder 特征上,进而达到控制图像生成的目的。
ControlNet 相比较于 Stable Diffusion,丰富了 Condition 的种类,V1 版本一共支持 9 类,包括 Canny, Sketch, Human Pose, Semantic, Depth, Normal Map 等。
ControlNet 的效果是非常惊人的,在开源社区得到了非常广泛的使用。

应用
从2021年1月 OpenAI 第一次推出 DALL-E,把文生图带入大众的视野,但现在,经过两年半的发展,文生图领域已经发生了翻天覆地的发展了。
一方面,以 midjourney 为代表的商业公司,提供文生图的订阅服务。midjourney 的生成在迭代了几个版本,特别是 v4 之后,效果非常惊艳,很多设计师拿它来提高工作效率。
另外一方面,开源社区利用 Stable Diffusion 框架也取得了长足的发展; 其中 novelai 这家日本公司,利用二次元数据对 Stable Diffusion 模型进行了 finetune,使得利用 SD 网络可以生成二次元形象。此外 C站 有大量魔改的网络模型,在各种细分场景下生成效果也非常惊人。
以上就是文生图 Diffusion 模型的大致发展路径。