2 Transformer的实现和代码解读
2.1 Transformer原理分析:
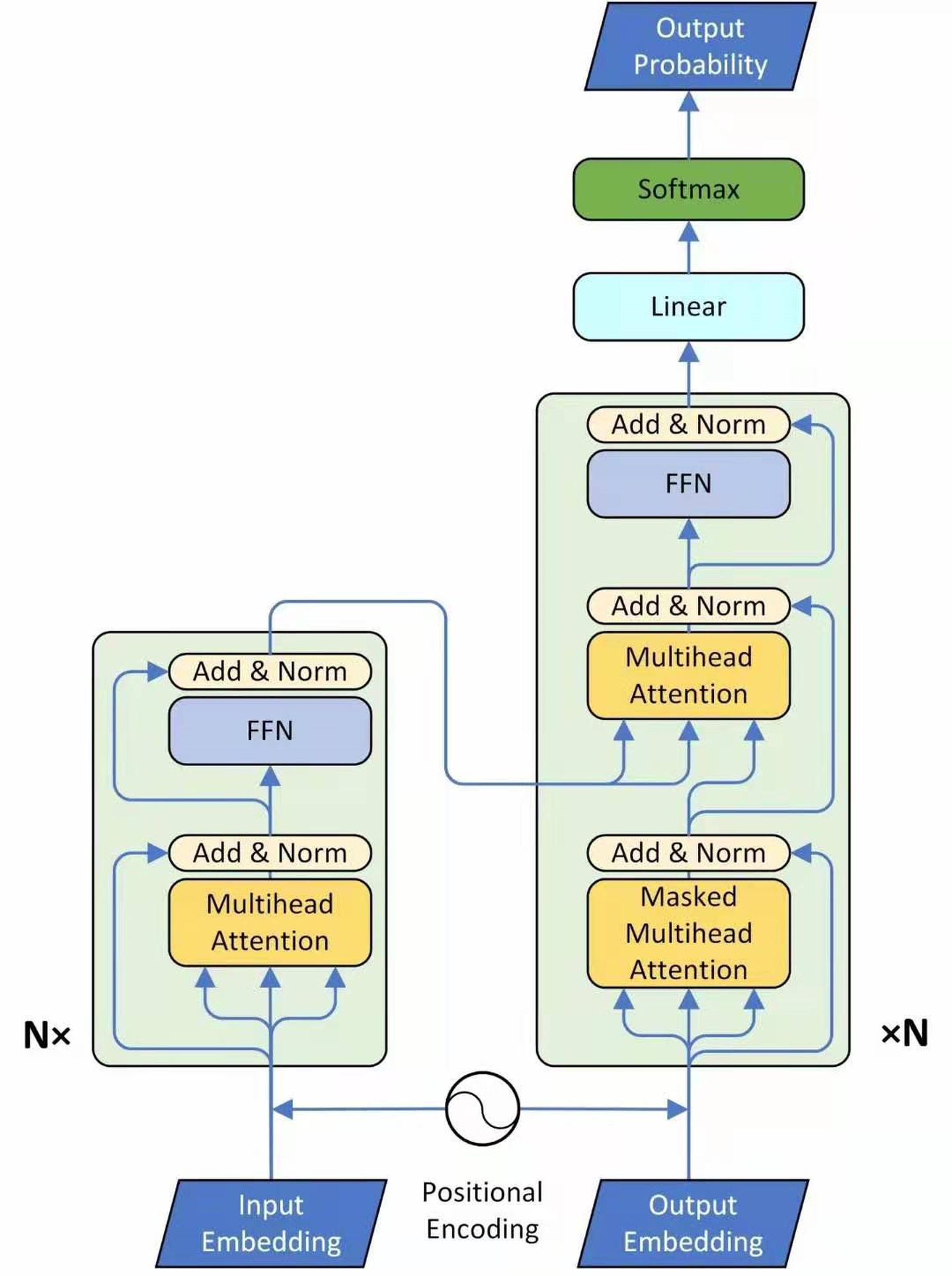
Encoder
图1是一个seq2seq的模型,左侧为Encoder block,右侧为Decoder block。红色圈中的部分为Multi-Head Attention,是由多个Self-Attention组成的。Encoder block包含一个Multi-Head Attention, Decoder block包含两个Multi-Head Attention(其中有一个用到Masked)。Multi-Head Attention上方还包括一个Add & Norm 层,Add表示残差连接(Residual Connection)用于防止网络退化。Norm 表示Layer Normalization,用于对每一层的激活值进行归一化。比如说在Encoder input处的输入是机器学习,在Decoder Input处的输入是,输出是machine。再下一个时刻在Decoder Input处的输入是machine,输出是learning。不断重复直到输出是句点(.)代表翻译结束。
Encoder: 首先输入 X ∈ R(nx, N)通过一个Input Embedding的转移矩阵 Wx ∈ R(d, nx)变为一个张量,即上文所述的 I ∈ R(d, N),再加上一个表示位置的Positional Encoding E ∈ R(d, N),得到一个张量。
进入绿色block,绿色的block会重复N次。绿色Block的第1层是一个上文讲的multi-head的attention。现在一个sequence I ∈ R(d, N)经过一个multi-head 的attention,会得到另外一个sequence O ∈ R(d, N).
下一个Layer是Add & Norm,这里的意思是:把multi-head的attention的layer的输入 I ∈ R(d, N)和输出O ∈ R(d, N)进行相加以后,再做Layer Normalization。

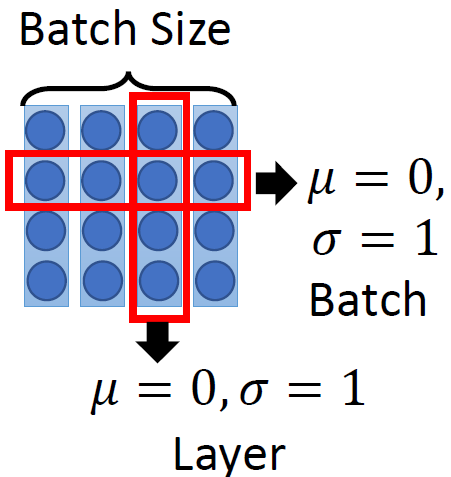
Batch Normalization强行让一个batch的数据的某个channel的 μ=0,σ=1,而Layer Normalization让一个数据的所有channel的μ=0,σ=1。
接着是一个Feed Forward的前馈网络和一个Add & Norm Layer。 所以,这一个绿色的block的前2个Layer操作的表达式为:
O1 = LayerNormalization(I + Multi-head Self-Attention(I))
这一个绿色的block的后2个Layer操作的表达式为:
O2 = LayerNormalization(O1 + FeedForwardNetwork(O1)) Block(I) = O2
所以Transformer的Encoder的整体操作为:
Encoder(I) = Block(..Block(Block)(I))
Decoder:
现在来看Decoder的部分,输入包括2部分,下方是前一个timestep的输出的embedding,即上文所述的I ∈ R(d,N),再加上一个表示位置的Positional Encoding E ∈ R(d,N),得到一个张量,去往后面的操作。它进入了绿色的block,绿色的block会重复N次。
绿色block里面的内容,首先是Masked Multi-Head Self-attention,masked的意思是使attend on已经产生的sequence,这个很合理,因为还没有产生出来的东西是不存在的,就无法做attention。
输出是: 对应 i 位置的输出词的概率分布 输入是: Encoder 的输出和对应 i-1 位置decoder的输出。所以中间的attention不是self-attention,它的key和value来自Encoder,Query来自上一位置Decoder的输出。
解码: 这里要特别注意一下,编码可以并行计算,一次性全部Encoding出来,但解码不是一次把所有序列解出来,而是像RNN一样一个一个解出来的,因为要用上一个位置的输入当作attention的query。
明确了解码过程之后最上面的图就很好懂了,这里主要的不同就是新加的attention多了一个mask,因为训练时的output都是Ground Truth,这样可以确保预测第i个位置时不会接触到未来的信息。
- 包含两个Multi-Head Attention层。
- 第一个Multi-Head Attention层采用了Masked操作。
- 第二个Multi-Head Attention层的key,value矩阵使用Encoder的编码信息矩阵C进行计算,而Query使用上一个Decoder block的输出计算。
- 最后有一个Softmax层计算下一个翻译单词的概率
下面详细介绍下Masked Multi-Head Self-attention的具体操作,Masked在Scale操作之后,softmax操作之前。
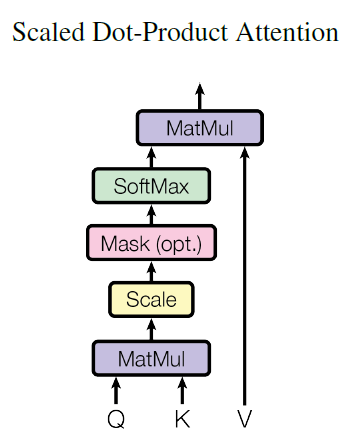
因为在翻译的过程中是顺序翻译的,即翻译完第i个单词,才可以翻译第 i+1 个单词。通过Masked操作可以防止第i个单词知道第i+1个单词之后的信息。下面以“我有一只猫”翻译成“I have a cat”为例,了解一下Masked操作。在Decoder的时候,是需要根据之前的翻译,求解当前最有可能的翻译,如下图所示。首先根据输入“”预测出第一个单词为“I”,然后根据输入“ I”预测下一个单词“have”。
Decoder 在训练的过程中使用 Teacher Forcing并且并行化训练,即将正确的单词序列( I have a cat)和对应输出(I have a cat ) 传递到Decoder。那么在预测第i个输出时,就要将第i+1之后的单词掩盖住,注意Mask操作是在Self-Attention的softmax之前使用的,下面用0 1 2 3 4 5分别表示" I have a cat "。
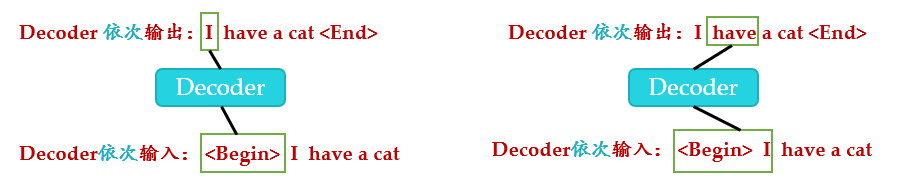
注意这里transformer模型训练和测试的方法不同:
测试时:
- 输入,解码器输出 I
- 输入前面已经解码的和I,解码器输出have
- 输入已经解码的, I, have, a, cat, 解码器输出解码结束标志位,每次解码都会利用前面已经解码输出的所有单词嵌入信息。